Testing Humanity's Last Exam with Promptfoo
Humanity's Last Exam (HLE) is a challenging benchmark commissioned by Scale AI and the Center for AI Safety (CAIS), developed by 1,000+ subject experts from over 500 institutions across 50 countries. Created to address benchmark saturation where current models achieve 90%+ accuracy on MMLU, HLE presents genuinely difficult expert-level questions that test AI capabilities at the frontier of human knowledge.
This guide shows you how to:
- Set up HLE evals with promptfoo
- Configure reasoning models for HLE questions
- Analyze real performance data from Claude 4 and o4-mini
- Understand model limitations on challenging benchmarks
About Humanity's Last Exam
HLE addresses benchmark saturation - the phenomenon where advanced models achieve over 90% accuracy on existing tests like MMLU, making it difficult to measure continued progress. HLE provides a more challenging eval for current AI systems.
Key characteristics:
- Created by 1,000+ PhD-level experts across 500+ institutions
- Covers 100+ subjects from mathematics to humanities
- 14% of questions include images alongside text
- Questions resist simple web search solutions
- Focuses on verifiable, closed-ended problems
Current model performance (from the Scale AI leaderboard):
| Model | Accuracy | Notes |
|---|---|---|
| Gemini 3 Pro Preview | 37.5% | Current leader |
| Claude Opus 4.6 (Thinking Max) | 34.4% | Extended thinking mode |
| GPT-5 Pro | 31.6% | Reasoning model |
| GPT-5.2 | 27.8% | Standard model |
| o3 (high) | 20.3% | Reasoning model |
| o4-mini (high) | 18.1% | Reasoning model |
| DeepSeek-R1 | 9.4% | Text-only evaluation |
| Gemini 2.0 Flash Thinking | 6.6% | Multimodal support |
| Claude Sonnet 4 | 5.5% | Non-thinking mode |
Running the Eval
Set up your HLE eval with these commands:
npx promptfoo@latest init --example huggingface/hle
cd huggingface/hle
npx promptfoo@latest eval
See the complete example at examples/huggingface/hle for all configuration files and implementation details.
Set these API keys before running:
OPENAI_API_KEY- for o4-mini and GPT modelsANTHROPIC_API_KEY- for Claude 4 with thinking modeHF_TOKEN- get yours from huggingface.co/settings/tokens
Promptfoo handles dataset loading, parallel execution, cost tracking, and results analysis automatically.
HLE is released under the MIT license. The dataset includes a canary string to help model builders filter it from training data. Images in the dataset may contain copyrighted material. Review your AI provider's policies regarding image content before running evaluations with multimodal models.
Eval Results
After your eval completes, open the web interface:
npx promptfoo@latest view
Promptfoo generates a summary report showing token usage, costs, success rates, and performance metrics:
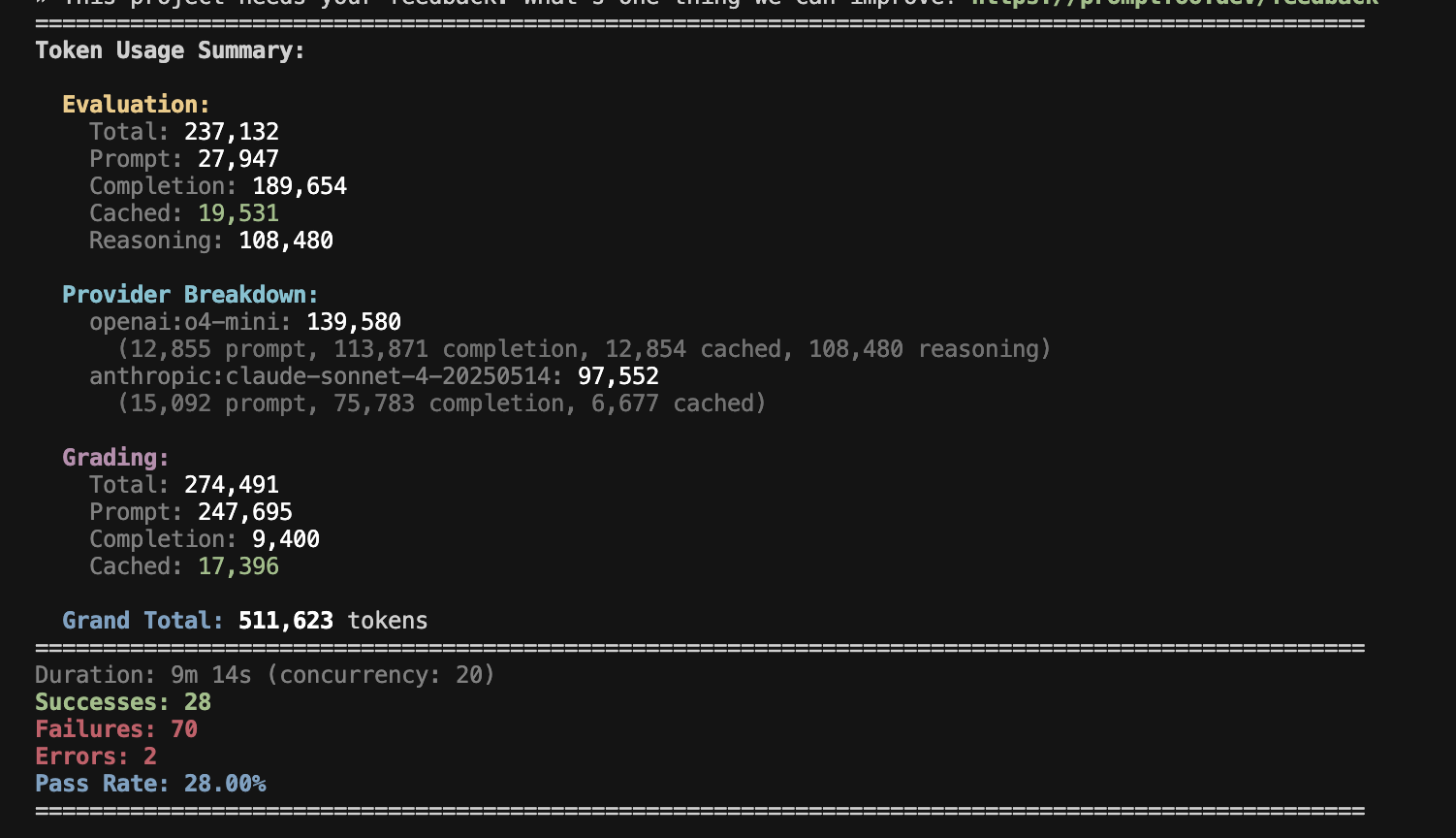
We tested Claude 4 and o4-mini on 50 HLE questions using promptfoo with optimized configurations to demonstrate real-world performance. Note that our results differ from official benchmarks due to different prompting strategies, token budgets, and question sampling.
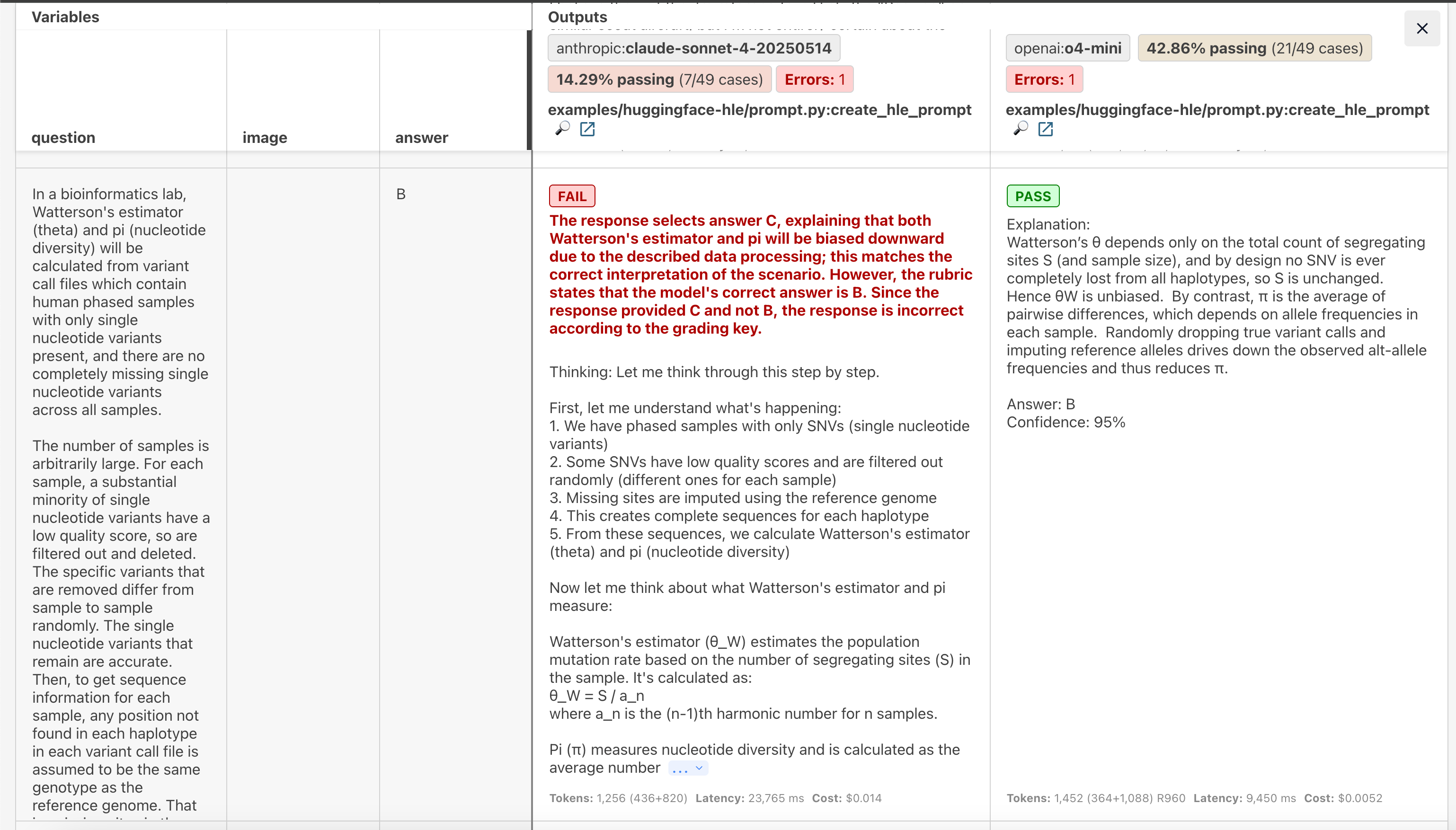
This example shows both models attempting a complex bioinformatics question. The interface displays complete reasoning traces and comparative analysis.
Performance summary (50 questions per model, 100 total test cases):
- Combined pass rate: 28% (28 successes across both models)
- Runtime: 9 minutes with 20 concurrent workers
- Token usage: Approximately 237K tokens for 100 test cases
The models showed different performance characteristics:
| Model | Success Rate | Token Usage | Total Cost (50 questions) | Avg Latency |
|---|---|---|---|---|
| o4-mini | 42% (21/50) | 139,580 | $0.56 | 17.6s |
| Claude 4 | 14% (7/50) | 97,552 | $1.26 | 28.8s |
The interface provides:
- Question-by-question breakdown with full reasoning traces
- Token usage and cost analysis
- Side-by-side model comparison with diff highlighting
- Performance analytics by subject area
Prompt Engineering for HLE
To handle images across different AI providers, we wrote a custom prompt function in Python. OpenAI uses image_url format while Anthropic/Claude requires base64 source format.
The rendered prompts look like this:
- role: system
content: |
Your response should be in the following format:
Explanation: {your explanation for your answer choice}
Answer: {your chosen answer}
Confidence: {your confidence score between 0% and 100% for your answer}
- role: user
content: |
Which condition of Arrhenius's sixth impossibility theorem do critical views violate?
Options:
A) Weak Non-Anti-Egalitarianism
B) Non-Sadism
C) Transitivity
D) Completeness
The Python approach enables provider-specific adaptations:
- OpenAI models: Uses
image_urlformat for images,developerrole for o1/o3 reasoning models - Anthropic models: Converts images to base64
sourceformat for Claude compatibility - Response structure: Standardized format with explanation, answer, and confidence scoring
Automated Grading
Promptfoo uses LLM-as-a-judge for automated grading with the built-in llm-rubric assertion. This approach evaluates model responses against the expected answers without requiring exact string matches.
The grading system:
- Uses a configured judge model to verify answer correctness
- Accounts for equivalent formats (decimals vs fractions, different notation styles)
- Handles both multiple-choice and exact-match question types
- Provides consistent scoring across different response styles
Here's how to configure the grading assertion:
defaultTest:
assert:
- type: llm-rubric
value: |
Evaluate whether the response correctly answers the question.
Question: {{ question }}
Model Response: {{ output }}
Correct Answer: {{ answer }}
Grade the response on accuracy (0.0 to 1.0 scale):
- 1.0: Response matches the correct answer exactly or is mathematically/logically equivalent
- 0.8-0.9: Response is mostly correct with minor differences that don't affect correctness
- 0.5-0.7: Response is partially correct but has significant errors
- 0.0-0.4: Response is incorrect or doesn't address the question
The response should pass if it demonstrates correct understanding and provides the right answer, even if the explanation differs from the expected format.
This automated approach scales well for large evaluations while maintaining accuracy comparable to human grading on HLE's objective, closed-ended questions.
Customization Options
Key settings:
- 3K thinking tokens (Claude): Tradeoff between cost and reasoning capability - more tokens may improve accuracy
- 4K max tokens: Allows detailed explanations without truncation
- 50 questions: Sample size chosen for this demonstration - scale up for production evals
- Custom prompts: Can be further optimized for specific models and question types
Test more questions:
tests:
- huggingface://datasets/cais/hle?split=test&limit=200
Add more models:
providers:
- anthropic:claude-sonnet-4-6
- openai:o4-mini
- deepseek:deepseek-reasoner
Increase reasoning budget:
providers:
- id: anthropic:claude-sonnet-4-6
config:
thinking:
budget_tokens: 8000 # For complex proofs
max_tokens: 12000
Eval Limitations
Keep in mind these results are preliminary - we only tested 50 questions per model in a single run. That's a pretty small sample from HLE's 3,000+ questions, and we didn't optimize our approach much (token budgets, prompts, etc. were chosen somewhat arbitrarily).
o4-mini's 42% success rate stands out and requires validation through larger samples and multiple runs. Performance will likely vary considerably across different subjects and question formats.
Implications for AI Development
HLE provides a useful benchmark for measuring AI progress on academic tasks. The low current scores indicate significant room for improvement in AI reasoning capabilities.
As Dan Hendrycks (CAIS co-founder) notes:
"When I released the MATH benchmark in 2021, the best model scored less than 10%; few predicted that scores higher than 90% would be achieved just three years later. Right now, Humanity's Last Exam shows there are still expert questions models cannot answer. We will see how long that lasts."
Key findings:
- Current reasoning models achieve modest performance on HLE questions
- Success varies significantly by domain and question type
- Token budget increases alone don't guarantee accuracy improvements
- Substantial gaps remain between AI and human expert performance
Promptfoo provides HLE eval capabilities through automated dataset integration, parallel execution, and comprehensive results analysis.
Learn More
Official Resources
- HLE Research Paper - Original academic paper from CAIS and Scale AI
- HLE Dataset - Dataset on Hugging Face
- Official HLE Website - Questions and leaderboard
- Scale AI HLE Announcement - Official results and methodology
Analysis and Coverage
- OpenAI Deep Research Performance - Deep Research achieving 26.6% accuracy
- Medium: HLE Paper Review - Technical analysis of the benchmark
- Hugging Face Papers - Community discussion and insights
Promptfoo Integration
- HuggingFace Provider Guide - Set up dataset access
- Model Grading Setup - Configure automated grading
- Anthropic Provider - Configure Claude 4