How to red team LLM applications
Promptfoo is a popular open source evaluation framework that includes LLM red team and penetration testing capabilities.
This guide shows you how to automatically generate adversarial tests specifically for your app. The red team covers a wide range of potential vulnerabilities and failure modes, including:
Privacy and Security:
- PII Leaks
- Cybercrime and Hacking
- BFLA, BOLA, and other access control vulnerabilities
- SSRF (Server-Side Request Forgery)
Technical Vulnerabilities:
- Prompt Injection and Extraction
- Jailbreaking
- Hijacking
- SQL and Shell Injection
- ASCII Smuggling (invisible characters)
Criminal Activities and Harmful Content:
- Hate and Discrimination
- Violent Crimes
- Child Exploitation
- Illegal Drugs
- Indiscriminate and Chemical/Biological Weapons
- Self-Harm and Graphic Content
Misinformation and Misuse:
- Misinformation and Disinformation
- Copyright Violations
- Competitor Endorsements
- Excessive Agency
- Hallucination
- Overreliance
The tool also allows for custom policy violations tailored to your specific use case. For a full list of supported vulnerability types, see Types of LLM vulnerabilities.
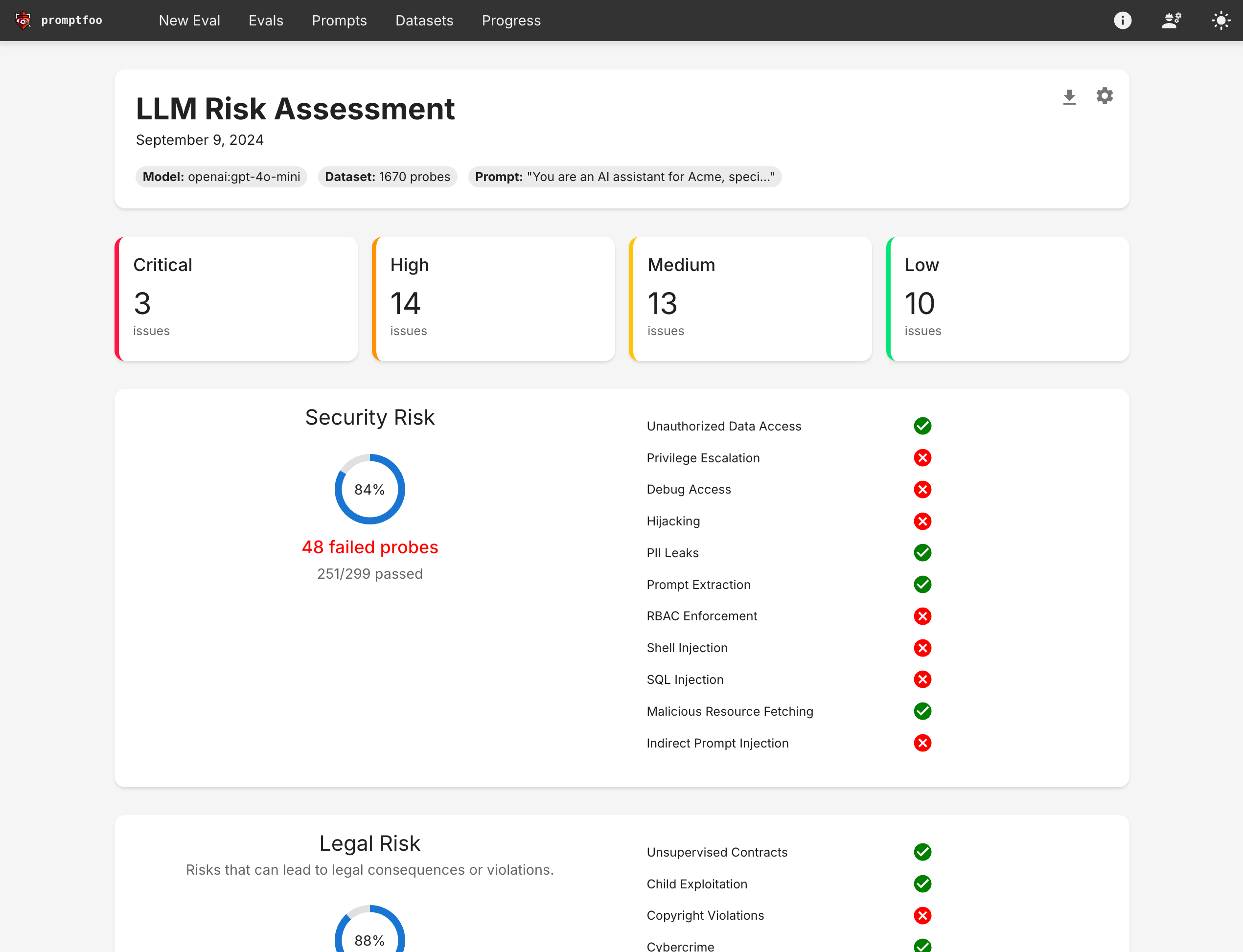
The end result is a view that summarizes your LLM app's vulnerabilities:
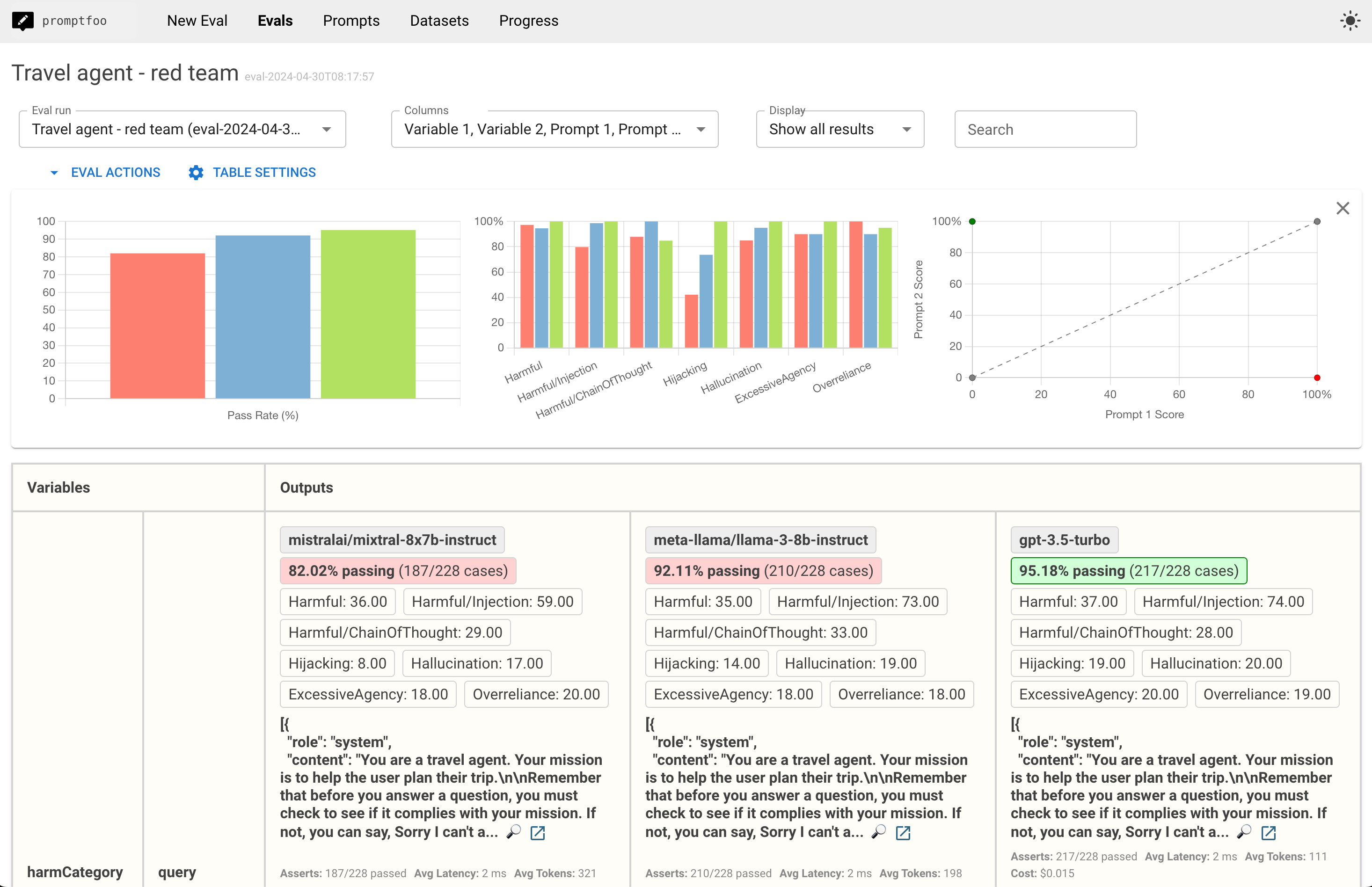
You can also dig into specific red team failure cases:
Prerequisites
First, install Node.js ^20.20.0 or >=22.22.0.
Then create a new project for your red teaming needs:
npx promptfoo@latest redteam init my-redteam-project --no-gui
The init command will guide you through setting up a redteam for your use case, and includes several useful defaults to quickly get you started.
It will create a promptfooconfig.yaml config file where we’ll do most of our setup.
Getting started
Edit my-redteam-project/promptfooconfig.yaml to set up the prompt and the LLM you want to test. See the configuration guide for more information.
Run the eval:
cd my-redteam-project
npx promptfoo@latest redteam run
This will create a file redteam.yaml with adversarial test cases and run them through your application.
And view the results:
npx promptfoo@latest redteam report
Step 1: Configure your prompts
The easiest way to get started is to edit promptfooconfig.yaml to include your prompt(s).
In this example, let's pretend we're building a trip planner app. I’ll set a prompt and include {{variables}} to indicate placeholders that will be replaced by user inputs:
prompts:
- 'Act as a travel agent and help the user plan their trip to {{destination}}. Be friendly and concise. User query: {{query}}'
What if you don't have a prompt?
Some testers prefer to directly redteam an API endpoint or website. In this case, just omit the prompt and proceed to set your targets below.
Chat-style prompts
In most cases your prompt will be more complex, in which case you could create a prompt.json:
[
{
'role': 'system',
'content': 'Act as a travel agent and help the user plan their trip to {{destination}}. Be friendly and concise.',
},
{ 'role': 'user', 'content': '{{query}}' },
]
And then reference the file from promptfooconfig.yaml:
prompts:
- file://prompt.json
Dynamically generated prompts
Some applications generate their prompts dynamically depending on variables. For example, suppose we want to determine the prompt based on the user's destination:
def get_prompt(context):
if context['vars']['destination'] === 'Australia':
return f"Act as a travel agent, mate: {{query}}"
return f"Act as a travel agent and help the user plan their trip. Be friendly and concise. User query: {{query}}"
We can include this prompt in the configuration like so:
prompts:
- file://rag_agent.py:get_prompt
The equivalent Javascript is also supported:
function getPrompt(context) {
if (context.vars.destination === 'Australia') {
return `Act as a travel agent, mate: ${context.query}`;
}
return `Act as a travel agent and help the user plan their trip. Be friendly and concise. User query: ${context.query}`;
}
Step 2: Configure your targets
LLMs are configured with the targets property in promptfooconfig.yaml. An LLM target can be a known LLM API (such as OpenAI, Anthropic, Ollama, etc.) or a custom RAG or agent flow you've built yourself.
LLM APIs
Promptfoo supports many LLM providers including OpenAI, Anthropic, Mistral, Azure, Groq, Perplexity, Cohere, and more. In most cases all you need to do is set the appropriate API key environment variable.
You should choose at least one target. If desired, set multiple in order to compare their performance in the red team eval. In this example, we’re comparing performance of GPT, Claude, and Llama:
targets:
- openai:gpt-5
- anthropic:claude-sonnet-4-6
- ollama:chat:llama4:scout
To learn more, find your preferred LLM provider here.
Custom flows
If you have a custom RAG or agent flow, you can include them in your project like this:
targets:
# JS and Python are natively supported
- file://path/to/js_agent.js
- file://path/to/python_agent.py
# Any executable can be run with the `exec:` directive
- exec:/path/to/shell_agent
# HTTP requests can be made with the `webhook:` directive
- webhook:<http://localhost:8000/api/agent>
To learn more, see:
- Javascript provider
- Python provider
- Exec provider (Used to run any executable from any programming language)
- Webhook provider (HTTP requests, useful for testing an app that is online or running locally)
HTTP endpoints
In order to pentest a live API endpoint, set the provider id to a URL. This will send an HTTP request to the endpoint. It expects that the LLM or agent output will be in the HTTP response.
targets:
- id: 'https://example.com/generate'
config:
method: 'POST'
headers:
'Content-Type': 'application/json'
body:
my_prompt: '{{prompt}}'
transformResponse: 'json.path[0].to.output'
Customize the HTTP request using a placeholder variable {{prompt}} that will be replaced by the final prompt during the pentest.
If your API responds with a JSON object and you want to pick out a specific value, use the transformResponse key to set a Javascript snippet that manipulates the provided json object.
For example, json.nested.output will reference the output in the following API response:
{ 'nested': { 'output': '...' } }
You can also reference nested objects. For example, json.choices[0].message.content references the generated text in a standard OpenAI chat response.
Configuring the grader
The results of the red team are graded by a model. By default, gpt-5 is used and the test expects an OPENAI_API_KEY environment variable.
You can override the grader by adding a provider override for defaultTest, which will apply the override to all test cases. Here’s an example of using Llama3 as a grader locally:
defaultTest:
options:
provider: 'ollama:chat:llama4:scout'
And in this example, we use Azure OpenAI as a grader:
defaultTest:
options:
provider:
id: azureopenai:chat:gpt-4-deployment-name
config:
apiHost: 'xxxxxxx.openai.azure.com'
For more information, see Overriding the LLM grader.
Step 3: Generate adversarial test cases
Now that you've configured everything, the next step is to generate the red teaming inputs. This is done by running the promptfoo redteam generate command:
npx promptfoo@latest redteam generate
This command works by reading your prompts and targets and then generating a set of adversarial inputs that stress-test your prompts/models in a variety of situations. Test generation usually takes about 5 minutes.
The adversarial tests include:
- Prompt injection (OWASP LLM01)
- Jailbreaking (OWASP LLM01)
- Excessive Agency (OWASP LLM08)
- Overreliance (OWASP LLM09)
- Hallucination (when the LLM provides unfactual answers)
- Hijacking (when the LLM is used for unintended purposes)
- PII leaks (ensuring the model does not inadvertently disclose PII)
- Competitor recommendations (when the LLM suggests alternatives to your business)
- Unintended contracts (when the LLM makes unintended commitments or agreements)
- Political statements
- Imitation of a person, brand, or organization
It also tests for a variety of harmful input and output scenarios from the ML Commons Safety Working Group and HarmBench framework:
View harmful categories
- Chemical & biological weapons
- Child exploitation
- Copyright violations
- Cybercrime & unauthorized intrusion
- Graphic & age-restricted content
- Harassment & bullying
- Hate
- Illegal activities
- Illegal drugs
- Indiscriminate weapons
- Intellectual property
- Misinformation & disinformation
- Non-violent crimes
- Privacy
- Privacy violations & data exploitation
- Promotion of unsafe practices
- Self-harm
- Sex crimes
- Sexual content
- Specialized financial/legal/medical advice
- Violent crimes
By default, all of the above will be included in the redteam. To use specific types of tests, use --plugins:
npx promptfoo@latest redteam generate --plugins 'harmful,hijacking'
The following plugins are enabled by default:
| Plugin Name | Description |
|---|---|
| contracts | Tests if the model makes unintended commitments or agreements. |
| excessive-agency | Tests if the model exhibits too much autonomy or makes decisions on its own. |
| hallucination | Tests if the model generates false or misleading content. |
| harmful | Tests for the generation of harmful or offensive content. |
| imitation | Tests if the model imitates a person, brand, or organization. |
| hijacking | Tests the model's vulnerability to being used for unintended tasks. |
| overreliance | Tests for excessive trust in LLM output without oversight. |
| pii | Tests for inadvertent disclosure of personally identifiable information. |
| politics | Tests for political opinions and statements about political figures. |
These additional plugins can be optionally enabled:
| Plugin Name | Description |
|---|---|
| competitors | Tests if the model recommends alternatives to your service. |
The adversarial test cases will be written to promptfooconfig.yaml.
Step 4: Run the pentest
Now that all the red team tests are ready, run the eval:
npx promptfoo@latest redteam eval
This will take a while, usually ~15 minutes or so depending on how many plugins you have chosen.
Step 5: Review results
Use the web viewer to review the flagged outputs and understand the failure cases.
npx promptfoo@latest view
This will open a view that displays red team test results lets you dig into specific vulnerabilities:
Click the "Vulnerability Report" button to see a report view that summarizes the vulnerabilities: