Intro
promptfoo is an open-source CLI and library for evaluating and red-teaming LLM apps.
With promptfoo, you can:
- Build reliable prompts, models, and RAGs with benchmarks specific to your use-case
- Secure your apps with automated red teaming and pentesting
- Speed up evaluations with caching, concurrency, and live reloading
- Score outputs automatically by defining metrics
- Use as a CLI, library, or in CI/CD
- Use OpenAI, Anthropic, Azure, Google, HuggingFace, open-source models like Llama, or integrate custom API providers for any LLM API
The goal: test-driven LLM development, not trial-and-error.
- Red teaming - Scan for security vulnerabilities and compliance risks
- Evaluations - Test quality and accuracy of your prompts, models, and applications
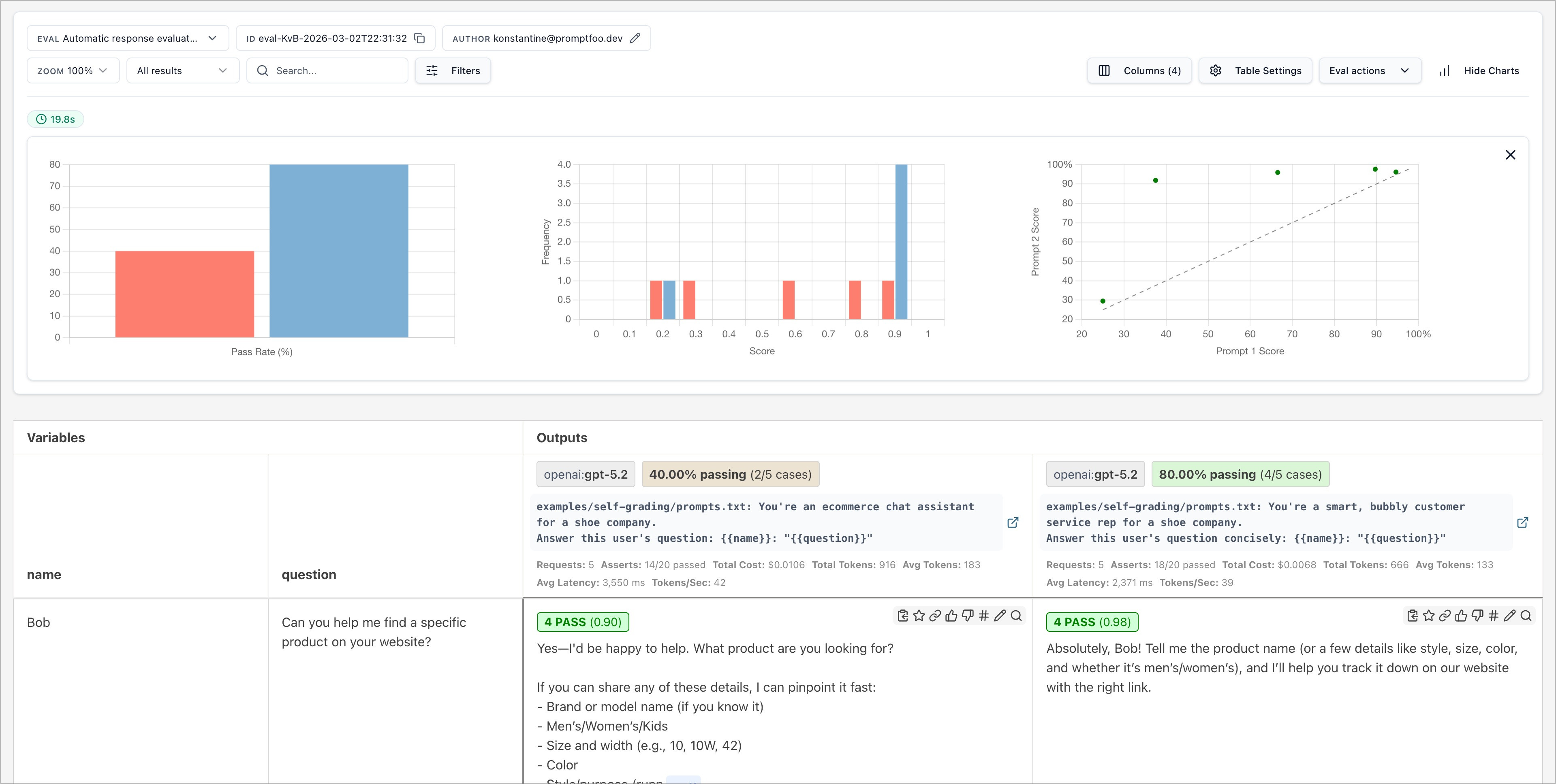
promptfoo produces matrix views that let you quickly evaluate outputs across many prompts.
Here's an example of a side-by-side comparison of multiple prompts and inputs:
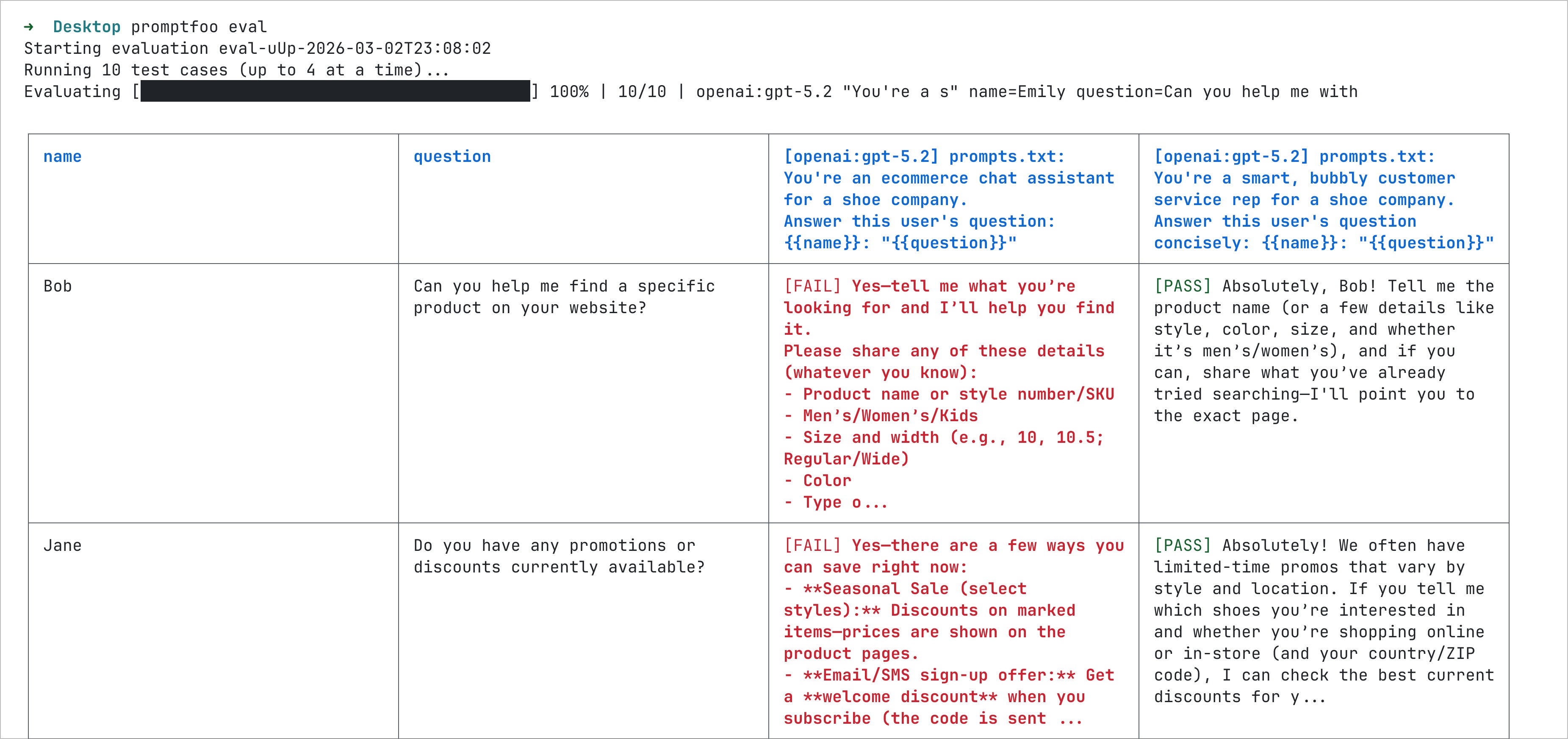
It works on the command line too.
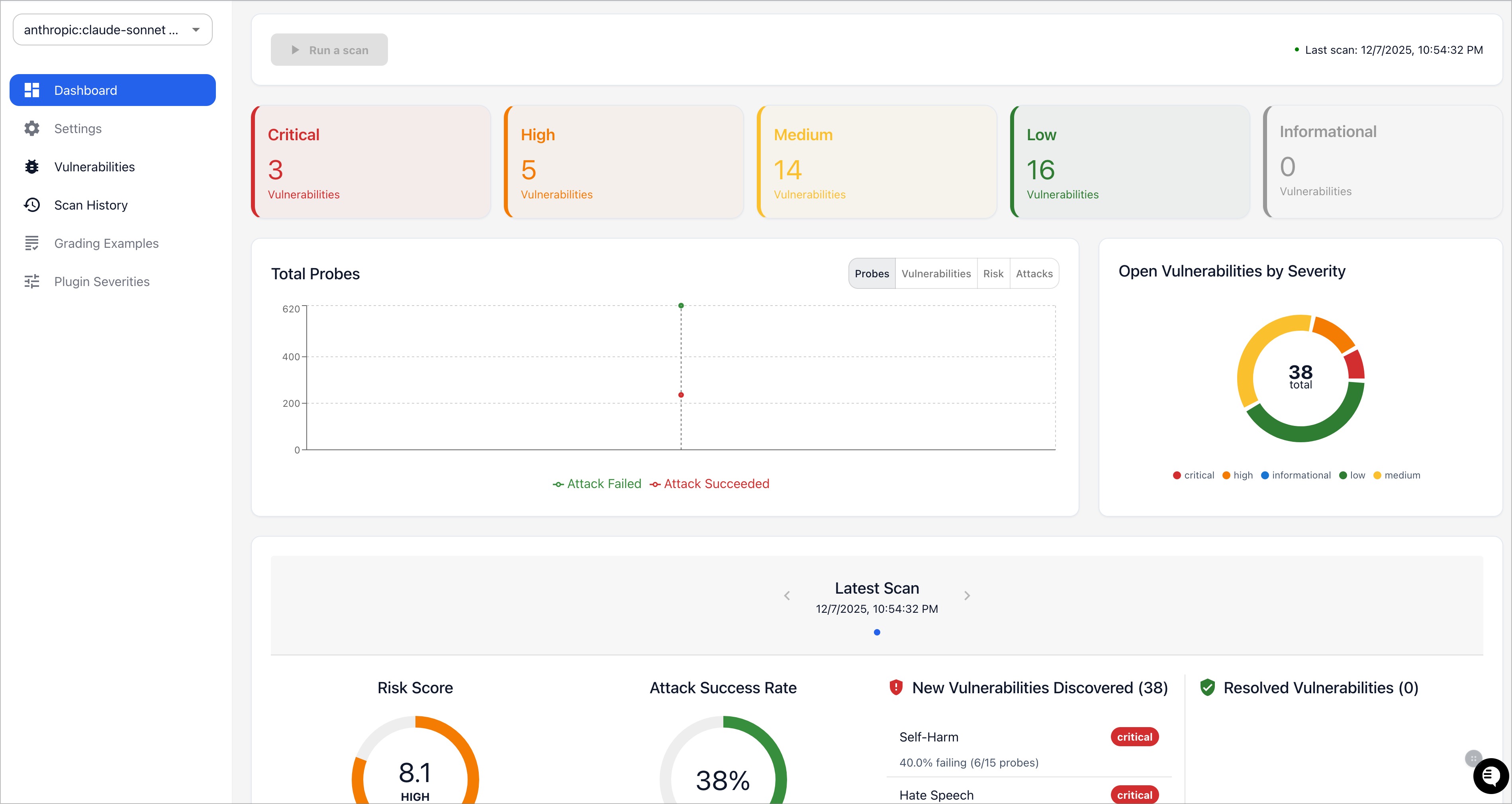
Promptfoo also produces high-level vulnerability and risk reports:
Why choose promptfoo?
There are many different ways to evaluate prompts. Here are some reasons to consider promptfoo:
- Developer friendly: promptfoo is fast, with quality-of-life features like live reloads and caching.
- Battle-tested: Originally built for LLM apps serving over 10 million users in production. Our tooling is flexible and can be adapted to many setups.
- Simple, declarative test cases: Define evals without writing code or working with heavy notebooks.
- Language agnostic: Use Python, Javascript, or any other language.
- Share & collaborate: Built-in share functionality & web viewer for working with teammates.
- Open-source: LLM evals are a commodity and should be served by 100% open-source projects with no strings attached.
- Private: This software runs completely locally. The evals run on your machine and talk directly with the LLM.
Workflow and philosophy
Test-driven prompt engineering is much more effective than trial-and-error.
Serious LLM development requires a systematic approach to prompt engineering. Promptfoo streamlines the process of evaluating and improving language model performance.
- Define test cases: Identify core use cases and failure modes. Prepare a set of prompts and test cases that represent these scenarios.
- Configure evaluation: Set up your evaluation by specifying prompts, test cases, and API providers.
- Run evaluation: Use the command-line tool or library to execute the evaluation and record model outputs for each prompt.
- Analyze results: Set up automatic requirements, or review results in a structured format/web UI. Use these results to select the best model and prompt for your use case.
- Feedback loop: As you gather more examples and user feedback, continue to expand your test cases.
