GPT-5 vs GPT-5-mini: MMLU Benchmark Comparison
This guide compares GPT-5 and GPT-5-mini on MMLU academic reasoning tasks using promptfoo.
MMLU (Massive Multitask Language Understanding) tests language models across 57 academic subjects including mathematics, physics, history, law, and medicine using multiple-choice questions.
This guide shows you how to run MMLU benchmarks using promptfoo.
MMLU (Massive Multitask Language Understanding) covers 57 academic subjects from abstract algebra to formal logic, testing models' ability to reason through complex problems rather than simply pattern match.
MMLU serves as an effective benchmark for comparing reasoning capabilities because it requires systematic thinking across diverse academic domains. Running your own MMLU evaluation lets you verify published performance claims and evaluate whether model differences justify upgrading for your specific use cases.
npx promptfoo@latest init --example openai-gpt-5-vs-gpt-5-mini-mmlu
Prerequisites
- promptfoo CLI installed
- OpenAI API key (set as
OPENAI_API_KEY) - Hugging Face token (set as
HF_TOKEN)
Step 1: Basic Setup
Initialize and configure:
npx promptfoo@latest init gpt-5-mmlu-comparison
cd gpt-5-mmlu-comparison
export HF_TOKEN=your_token_here
Create a minimal configuration:
# yaml-language-server: $schema=https://promptfoo.dev/config-schema.json
description: GPT-5 vs GPT-5-mini MMLU comparison
prompts:
- |
Question: {{question}}
A) {{choices[0]}}
B) {{choices[1]}}
C) {{choices[2]}}
D) {{choices[3]}}
Answer:
providers:
- openai:gpt-5
- openai:gpt-5-mini
defaultTest:
assert:
- type: llm-rubric
value: |
Compare the model's answer to the correct answer: {{answer}}.
The model should select the correct choice and show clear reasoning.
Score as PASS if the answer is correct.
tests:
- huggingface://datasets/cais/mmlu?split=test&subset=abstract_algebra&limit=5
Step 2: Run and View Results
npx promptfoo@latest eval
npx promptfoo@latest view
You should see GPT-5 outperforming GPT-5-mini on reasoning questions.
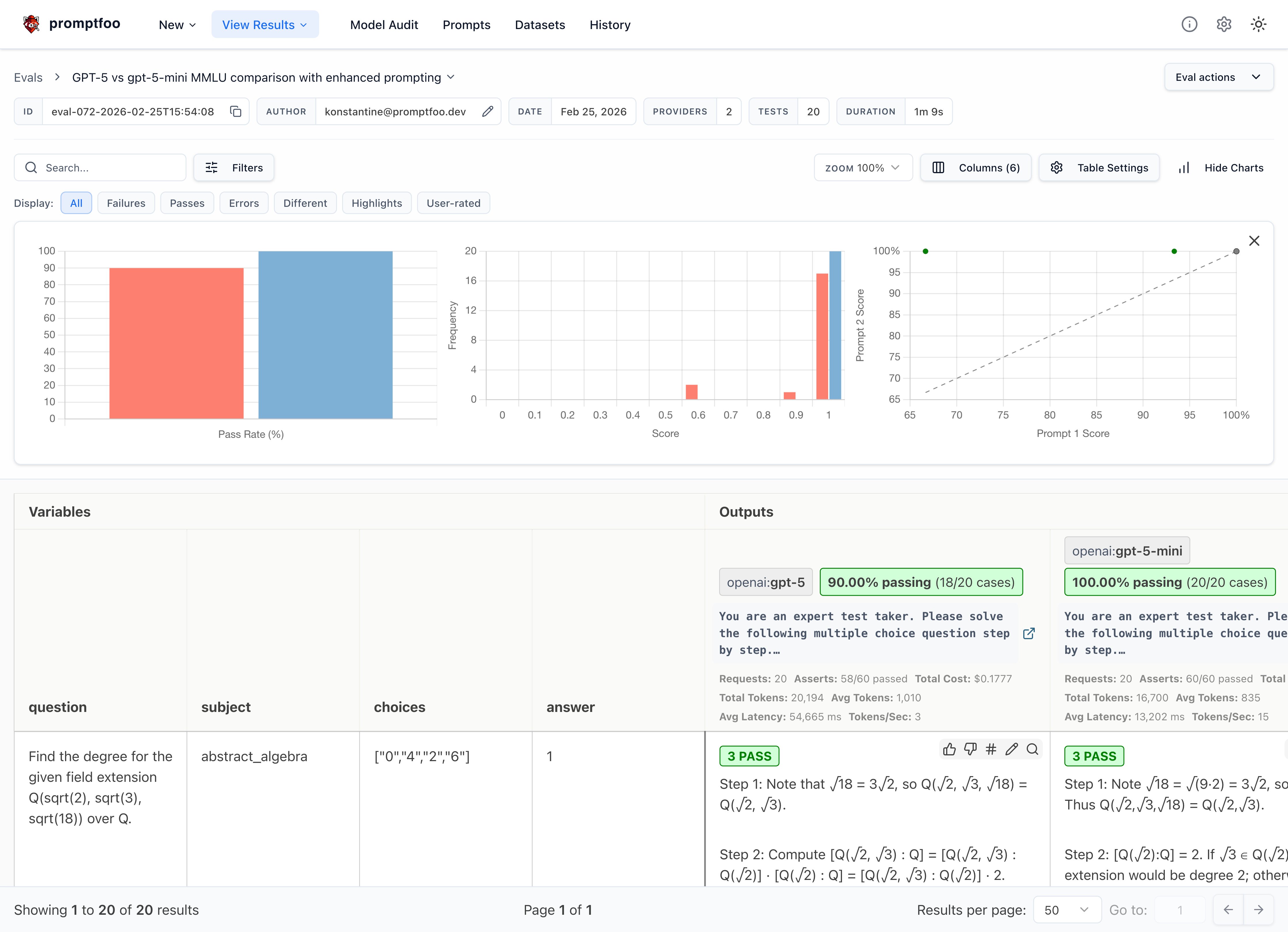
The results show side-by-side MMLU pass rates, letting you compare reasoning capabilities directly.
Step 3: Improve with Chain-of-Thought
Chain-of-Thought prompting significantly improves reasoning performance. Update your prompt:
prompts:
- |
You are an expert test taker. Solve this step by step.
Question: {{question}}
Options:
A) {{choices[0]}}
B) {{choices[1]}}
C) {{choices[2]}}
D) {{choices[3]}}
Think through this step by step, then provide your final answer as "Therefore, the answer is A/B/C/D."
providers:
- id: openai:gpt-5
config:
max_tokens: 1000
- id: openai:gpt-5-mini
config:
max_tokens: 1000
defaultTest:
assert:
- type: latency
threshold: 60000
- type: llm-rubric
value: |
Compare the model's answer to the correct answer: {{answer}}.
Check if the model:
1. Shows step-by-step reasoning
2. Arrives at the correct conclusion
3. Uses the requested format
Score as PASS if the answer is correct and reasoning is clear.
- type: regex
value: 'Therefore, the answer is [ABCD]'
tests:
- huggingface://datasets/cais/mmlu?split=test&subset=abstract_algebra&limit=10
- huggingface://datasets/cais/mmlu?split=test&subset=formal_logic&limit=10
Step 4: Scale Your Evaluation
Add more subjects for comprehensive testing:
tests:
# Mathematics & Logic
- huggingface://datasets/cais/mmlu?split=test&subset=abstract_algebra&limit=20
- huggingface://datasets/cais/mmlu?split=test&subset=college_mathematics&limit=20
- huggingface://datasets/cais/mmlu?split=test&subset=formal_logic&limit=20
# Sciences
- huggingface://datasets/cais/mmlu?split=test&subset=physics&limit=15
- huggingface://datasets/cais/mmlu?split=test&subset=chemistry&limit=15
Understanding Your Results
What to Look For
- Accuracy: GPT-5 should score higher across subjects
- Reasoning Quality: Look for clearer step-by-step explanations
- Format Compliance: Better adherence to answer format
- Consistency: More reliable performance across question types
Key Areas to Compare
When evaluating GPT-5 vs GPT-5-mini on MMLU, look for differences in:
- Mathematical Reasoning: Algebra, calculus, and formal logic performance
- Scientific Knowledge: Chemistry, physics, and biology understanding
- Chain-of-Thought: Structured reasoning in complex multi-step problems
- Error Reduction: Calculation mistakes and logical fallacies
- Context Retention: Handling of lengthy academic passages and complex questions
Next Steps
Ready to go deeper? Try these advanced techniques:
- Compare multiple prompting strategies - Test few-shot vs zero-shot approaches
- Explore MMLU-Pro - A more challenging version with 10 answer choices and complex reasoning questions
- Add domain-specific assertions - Create custom metrics for your use cases
- Scale with distributed testing - Run comprehensive benchmarks across all 57 MMLU subjects