GPT Model Tiers: MMLU-Pro Benchmark Comparison
This guide compares full, mini, and nano OpenAI GPT model tiers on MMLU-Pro reasoning tasks using promptfoo.
MMLU-Pro is a more challenging successor to MMLU with harder reasoning questions and up to 10 answer options per item.
This guide shows you how to run MMLU-Pro benchmarks using promptfoo.
MMLU-Pro covers a broad set of academic and professional subjects, and it is more useful than classic MMLU when current models are already near saturation on easier multiple-choice benchmarks.
Running your own MMLU-Pro eval lets you compare reasoning quality, latency, and cost on a benchmark where full-size, mini, and nano models are less likely to tie at a perfect score.
npx promptfoo@latest init --example compare-gpt-model-tiers-mmlu-pro
Prerequisites
- promptfoo CLI installed
- OpenAI API key (set as
OPENAI_API_KEY) - Hugging Face token (optional for public datasets; set as
HF_TOKEN)
Step 1: Basic Setup
Initialize and configure:
npx promptfoo@latest init --example compare-gpt-model-tiers-mmlu-pro
cd compare-gpt-model-tiers-mmlu-pro
export HF_TOKEN=your_token_here
Create a minimal configuration:
# yaml-language-server: $schema=https://promptfoo.dev/config-schema.json
description: GPT model tiers MMLU-Pro comparison
prompts:
- |
Question: {{question}}
{% for option in options -%}
{{ "ABCDEFGHIJ"[loop.index0] }}) {{ option }}
{% endfor %}
End with: Therefore, the answer is <LETTER>.
providers:
- openai:chat:gpt-5.4
- openai:chat:gpt-5.4-mini
- openai:chat:gpt-5.4-nano
defaultTest:
assert:
- type: regex
value: 'Therefore, the answer is [A-J]'
- type: javascript
value: |
const match = String(output).match(/Therefore,\s*the\s*answer\s*is\s*([A-J])/i);
return match?.[1]?.toUpperCase() === String(context.vars.answer).trim().toUpperCase();
tests:
- huggingface://datasets/TIGER-Lab/MMLU-Pro?split=test&config=default&limit=20
Step 2: Run and View Results
npx promptfoo@latest eval
npx promptfoo@latest view
You should see the full-size GPT tier outperforming the smaller tiers on at least some MMLU-Pro categories, though the exact gaps depend on the sample.
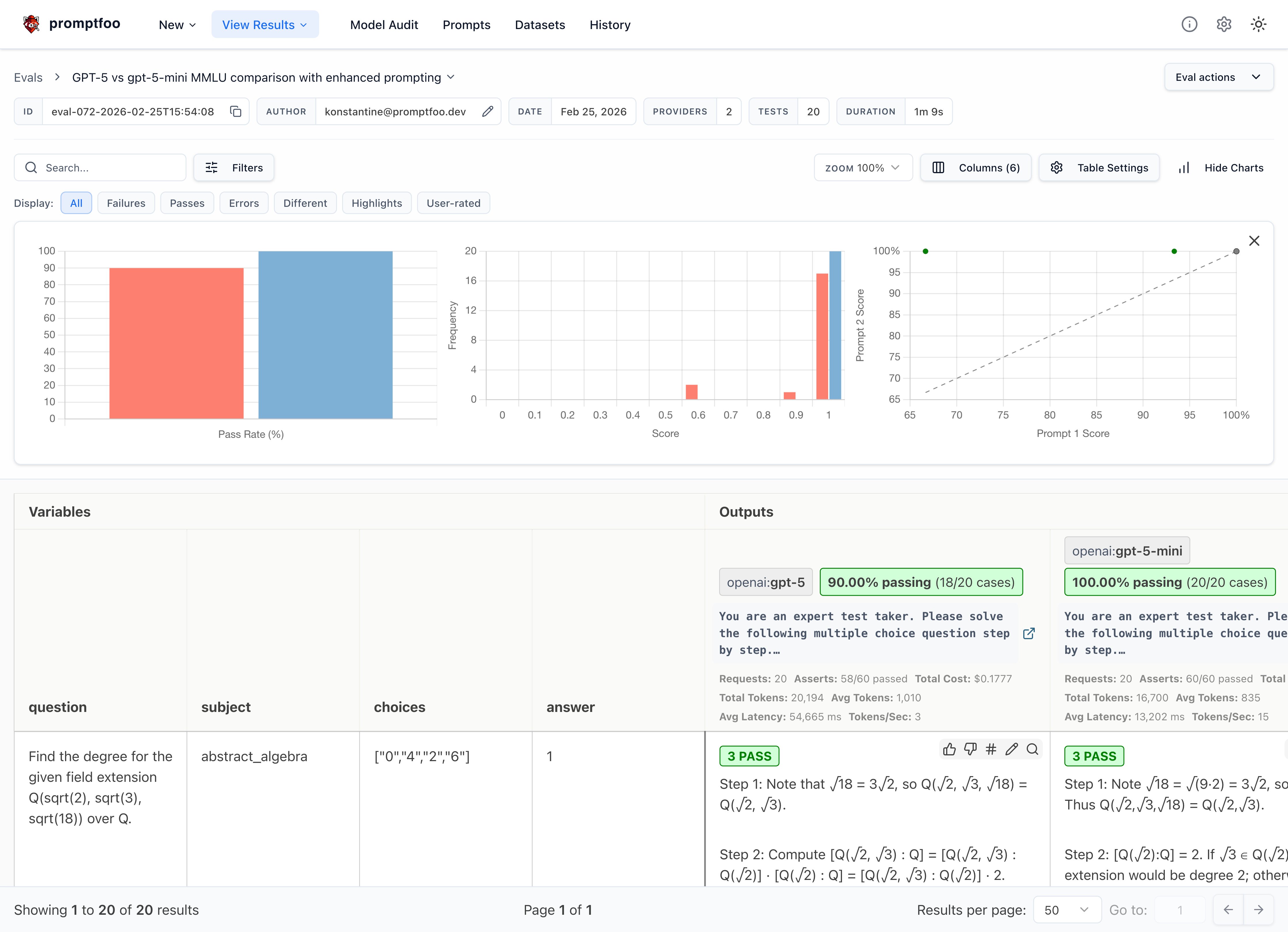
The results show side-by-side benchmark pass rates, letting you compare reasoning capabilities directly.
Step 3: Improve with Chain-of-Thought
Add a short reasoning instruction and fixed final-answer format:
prompts:
- |
You are an expert test taker. Solve this step by step.
Question: {{question}}
Options:
{% for option in options -%}
{{ "ABCDEFGHIJ"[loop.index0] }}) {{ option }}
{% endfor %}
Think through this step by step, then provide your final answer as "Therefore, the answer is A."
providers:
- id: openai:chat:gpt-5.4
config:
max_completion_tokens: 1200
- id: openai:chat:gpt-5.4-mini
config:
max_completion_tokens: 1200
- id: openai:chat:gpt-5.4-nano
config:
max_completion_tokens: 1200
defaultTest:
assert:
- type: latency
threshold: 60000
- type: regex
value: 'Therefore, the answer is [A-J]'
- type: javascript
value: |
const match = String(output).match(/Therefore,\s*the\s*answer\s*is\s*([A-J])/i);
return match?.[1]?.toUpperCase() === String(context.vars.answer).trim().toUpperCase();
tests:
- huggingface://datasets/TIGER-Lab/MMLU-Pro?split=test&config=default&limit=100
Step 4: Scale Your Eval
Increase the sample size for a broader benchmark pass:
tests:
- huggingface://datasets/TIGER-Lab/MMLU-Pro?split=test&config=default&limit=200
Understanding Your Results
What to Look For
- Accuracy: Full-size GPT models may score higher across harder subjects
- Reasoning Quality: Look for stronger elimination among similar distractors
- Format Compliance: Better adherence to answer format
- Consistency: More reliable performance across question types
Key Areas to Compare
When evaluating full, mini, and nano GPT model tiers on MMLU-Pro, look for differences in:
- Mathematical Reasoning: Algebra, calculus, and formal logic performance
- Scientific Knowledge: Chemistry, physics, and biology understanding
- Chain-of-Thought: Structured reasoning in complex multi-step problems
- Error Reduction: Calculation mistakes and logical fallacies
- Context Retention: Handling of lengthy academic passages and complex questions
Next Steps
Ready to go deeper? Try these advanced techniques:
- Compare multiple prompting strategies - Test few-shot vs zero-shot approaches
- Increase MMLU-Pro sample size - Use larger random subsets once your prompt and assertions are stable
- Add domain-specific assertions - Create custom metrics for your use cases
- Scale with distributed testing - Run broader MMLU-Pro benchmarks across more questions and categories