Evaluate OSWorld with Inspect
OSWorld is a computer-use benchmark for agents that operate a real desktop. A task may ask the model to edit a spreadsheet, use a browser, modify a document, or configure an app. The agent receives screenshots, uses mouse and keyboard tools, and is graded against the final VM state.
The integration-inspect-osworld example runs an OSWorld eval through Inspect and reports the score back to Promptfoo. Use this pattern when the benchmark already has a mature desktop harness and you want Promptfoo to own the config, assertions, result table, traces, and CI gate around it.
This guide shows you how to:
- run one real desktop task before paying for a larger benchmark
- scale from one sample to an app slice, then to the small and full suites
- separate scored model failures from provider or harness errors
- inspect the desktop trajectory when a result is surprising
OSWorld is useful because success is not judged from the final text alone. An
agent can answer DONE and still score 0.0 if the spreadsheet, slide deck, or
desktop state is wrong. That makes it a concrete example of why agent evals need
stateful graders, not only text assertions.
What runs
The default example uses Inspect's inspect_evals/osworld_small task, a smaller
OSWorld corpus packaged for Inspect. A second config,
promptfooconfig.full.yaml, switches to inspect_evals/osworld with
include_connected=true for every Inspect-supported full-corpus sample. In the
Inspect version used here, that means 21 default small-suite samples and 246
full-corpus samples. That full run is still an Inspect-supported subset of the
upstream OSWorld paper corpus, not all 369 upstream tasks.
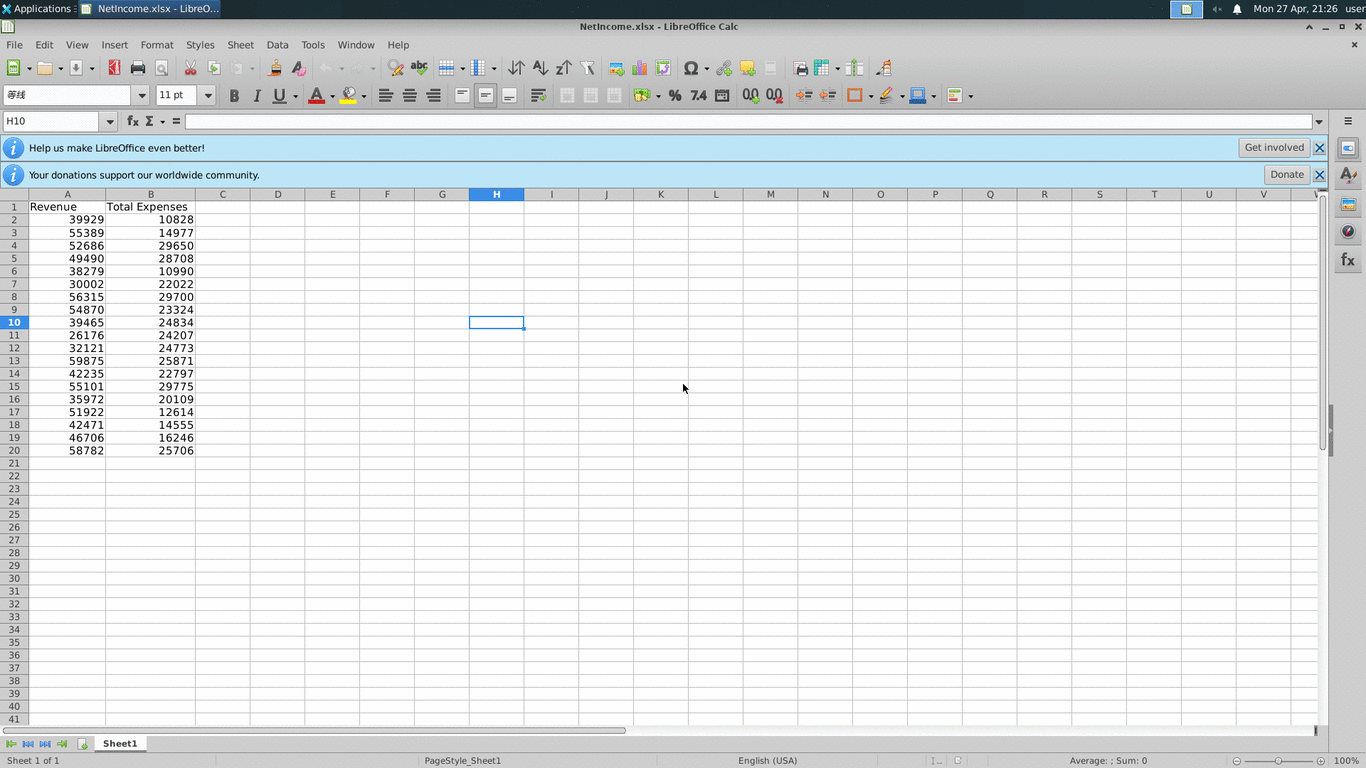
In the sample shown above, OSWorld opens NetIncome.xlsx in LibreOffice Calc and asks the agent to compute totals for the Revenue and Total Expenses columns on a new sheet. That is one generated row in the full suite. Inspect provides the Ubuntu desktop sandbox, screenshots, computer tool, model loop, and scorer.
Use a simple pass-through prompt such as {{prompt}} for Promptfoo's row label; Inspect reads the actual task instruction from the OSWorld dataset.
The dated full-corpus GPT-5.5 run later in this guide finished with 242 scored rows after reruns: 139 passes, 103 scored failures, and 4 repeated provider errors. Spreadsheet and document tasks were among the strongest clusters, while cross-app workflows and VLC were harder. Those results are useful both as a benchmark example and as a reminder that model capability and harness reliability must be reported separately.
How the wrapper works
The example is intentionally thin:
- Promptfoo calls
provider.pyonce for each test case. - The provider starts
inspect eval <task> --sample-id <id>. - Inspect runs the desktop sandbox and agent loop.
- Inspect writes a
.evallog with screenshots, model messages, tool calls, files, scores, and metadata. - The provider runs
inspect log dump, parses the sample score, and returns normal Promptfoo output and metadata. assertion.pypasses only when the OSWorld sample score is1.0.
This means Promptfoo owns orchestration and reporting. Inspect owns the agent runtime and OSWorld grading.
For each generated small-suite row, the provider effectively runs:
inspect eval inspect_evals/osworld_small \
--model openai/gpt-5.5 \
--sample-id 42e0a640-4f19-4b28-973d-729602b5a4a7 \
--log-dir /absolute/path/to/inspect_logs/<run>
inspect log dump /absolute/path/to/inspect_logs/<run>/<file>.eval
Implementation map
The example has six moving parts:
promptfooconfig.yamlis the small-suite Promptfoo entrypoint. It selects GPT-5.5, sets both timeouts, enables tracing, and loads OSWorld rows fromosworld_tests.py.promptfooconfig.full.yamlis the full-suite entrypoint. It switches the Inspect task toinspect_evals/osworld, setsinclude_connected=true, and loads the full generated row list.osworld_tests.pycalls Inspect's OSWorld task loader and returns one Promptfoo test case per supported small-suite or full-corpus sample, with app and sample metadata for filtering.provider.pyis a file provider withcall_api(prompt, options, context). It resolves paths to absolute locations, runs Inspect, dumps the.evalfile to JSON, and returns Promptfoo output plus metadata.assertion.pyreadscontext.providerResponse.metadata.scoreand turns the OSWorld scorer result into a normal Promptfoo pass or fail.inspect_logs/is gitignored run state. Inspect stores screenshots, model messages, tool calls, files, scorer output, and token usage there.
The provider treats three states differently:
score >= 1.0: Inspect completed and OSWorld scored the task as correct.score < 1.0: Inspect completed and OSWorld scored the task as incorrect.- provider
error: setup, Docker, model SDK, timeout, tool execution, log parsing, or missing scorer output prevented a scored sample from being produced.
Prerequisites
You need Docker because OSWorld runs a desktop environment:
- Docker Engine 24.0.6 or newer
- Docker Compose V2 available as
docker compose - Python with Inspect OSWorld and OpenTelemetry dependencies
- The SDK and API key for the model provider you choose
Install the Python dependencies:
pip install 'inspect-evals[osworld]' openai anthropic opentelemetry-sdk opentelemetry-exporter-otlp-proto-http
For the default config, export OPENAI_API_KEY. To use Anthropic instead, export ANTHROPIC_API_KEY and override the model in the test vars or provider config.
The first run can build an OSWorld Docker image of roughly 8GB. Real runs can consume substantial time and tokens; use the verification ladder below instead of starting with the full suite.
Run the example
Create the example:
npx promptfoo@latest init --example integration-inspect-osworld
cd integration-inspect-osworld
Start with one exact sample:
PROMPTFOO_ENABLE_OTEL=true OTEL_EXPORTER_OTLP_ENDPOINT=http://127.0.0.1:4318 \
promptfoo eval -c promptfooconfig.yaml --no-cache \
--filter-metadata sample_id=42e0a640-4f19-4b28-973d-729602b5a4a7
Then broaden to an app subset once the wrapper works end to end:
PROMPTFOO_ENABLE_OTEL=true OTEL_EXPORTER_OTLP_ENDPOINT=http://127.0.0.1:4318 \
promptfoo eval -c promptfooconfig.yaml --no-cache \
--filter-metadata app=libreoffice_calc --max-concurrency 1 \
-o osworld-libreoffice-calc.json
App filters are still multi-sample runs. In the current osworld_small set,
app=libreoffice_calc selects three samples; in one local GPT-5.5 verification
on April 29, 2026, that sequential subset took 12m31s and used 533,101 total
tokens. Treat that as scale guidance, not a fixed benchmark.
After the exact sample and app slice both work, run the full traced
osworld_small suite:
PROMPTFOO_ENABLE_OTEL=true OTEL_EXPORTER_OTLP_ENDPOINT=http://127.0.0.1:4318 \
promptfoo eval -c promptfooconfig.yaml --no-cache --max-concurrency 6 \
-o osworld-small-results.json
To run the same flow from the promptfoo repository source tree:
PROMPTFOO_ENABLE_OTEL=true OTEL_EXPORTER_OTLP_ENDPOINT=http://127.0.0.1:4318 \
npm run local -- eval -c examples/integration-inspect-osworld/promptfooconfig.yaml --no-cache \
--max-concurrency 6 -o osworld-small-results.json
To run Inspect's full supported corpus through Promptfoo, use the dedicated full-suite config:
PROMPTFOO_ENABLE_OTEL=true OTEL_EXPORTER_OTLP_ENDPOINT=http://127.0.0.1:4318 \
promptfoo eval -c promptfooconfig.full.yaml --no-cache --max-concurrency 3 \
-o osworld-full-results.json
On a 6-vCPU, 16-GiB Colima VM, --max-concurrency 3 kept three desktop
containers active without oversubscribing the machine during the reference run.
Choose concurrency from the Docker VM's limits, not only from the host machine's
headline CPU and memory.
The full config intentionally includes connected samples, so it is more sensitive to runtime network conditions than the default small-suite config. It also raises the timeout budget because some full-suite Writer rows can exceed the small config's 30-minute limit:
providers:
- id: file://provider.py
config:
timeout: 7500000 # Promptfoo Python worker timeout, in ms
timeoutSeconds: 7200 # Inspect subprocess timeout, in seconds
Configuration
The provider config sets two timeouts because there are two execution layers:
providers:
- id: file://provider.py
label: OSWorld via Inspect
config:
defaultModel: openai/gpt-5.5
timeout: 1800000 # Promptfoo Python worker timeout, in ms
timeoutSeconds: 1800 # Inspect subprocess timeout, in seconds
Keep the tests block to one line. Put the shared assertion and trace metadata
in defaultTest, then load the OSWorld sample list with the standard
Python test generator pattern:
defaultTest:
metadata:
tracingEnabled: true
assert:
- type: python
value: file://assertion.py
tests: file://osworld_tests.py:generate_tests
The full-suite config changes the task and loader together:
providers:
- id: file://provider.py
label: OSWorld via Inspect
config:
defaultModel: openai/gpt-5.5
task: inspect_evals/osworld
taskParameters:
include_connected: true
tests: file://osworld_tests.py:generate_full_tests
osworld_tests.py delegates sample selection to Inspect. It loads the
supported OSWorld samples, derives app metadata from each sample's
example.json path, and returns normal Promptfoo test cases:
from pathlib import Path
from inspect_evals.osworld import osworld, osworld_small
CONTAINER_EXAMPLE_PATH = "/tmp/osworld/desktop_env/example.json"
def generate_tests():
dataset = osworld_small().dataset
return [_test_case(dataset[index]) for index in range(len(dataset))]
def generate_full_tests():
dataset = osworld(include_connected=True).dataset
return [_test_case(dataset[index]) for index in range(len(dataset))]
def _test_case(sample):
sample_id = str(sample.id)
instruction = str(sample.input)
app = _normalize_app(Path(sample.files[CONTAINER_EXAMPLE_PATH]).parent.name)
return {
"description": f"{app} - {' '.join(instruction.split())[:80]}",
"vars": {"prompt": instruction, "app": app, "sample_id": sample_id},
"metadata": {
"app": app,
"sample_id": sample_id,
"testCaseId": f"osworld-{app.replace('_', '-')}-{sample_id.split('-', 1)[0]}",
},
}
def _normalize_app(app):
normalized = str(app).strip().lower().replace("-", "_").replace(" ", "_")
return "vscode" if normalized == "vs_code" else normalized
Those generated vars arrive in provider.py as context["vars"]["app"] and
context["vars"]["sample_id"]. The metadata fields are filterable, so you can
run subsets without editing the dataset:
promptfoo eval -c promptfooconfig.yaml --filter-metadata app=vscode
promptfoo eval -c promptfooconfig.yaml \
--filter-metadata sample_id=42e0a640-4f19-4b28-973d-729602b5a4a7
The provider always passes sample_id to Inspect's --sample-id flag. Keep
app in the generated vars so results can still be grouped by OSWorld
application. The generated metadata normalizes VS Code to vscode; multi-app
tasks use multi_apps.
Use the run scopes intentionally:
mockllm/model --limit 0checks the Inspect CLI shape without model spend.--filter-metadata sample_id=...is the smallest real end-to-end validation.--filter-metadata app=...is a broader app slice and may include multiple samples.- No filter on
promptfooconfig.yamlruns the full small suite. promptfooconfig.full.yamlruns Inspect's full supported corpus and is the benchmark-style configuration.
The example enables Promptfoo tracing directly:
tracing:
enabled: true
otlp:
http:
enabled: true
port: 4318
host: 127.0.0.1
acceptFormats:
- json
- protobuf
defaultTest.metadata.tracingEnabled: true enables tracing for every generated
row. The loader's metadata.testCaseId gives each row a stable id so the trace
can be correlated with the result.
Read the results
The provider returns the OSWorld sample id, score, status, final assistant text, token usage, and path to the Inspect log:
{
"inspect_log_path": "/absolute/path/to/inspect_logs/.../*.eval",
"score": 0.0,
"status": "fail",
"sample_id": "42e0a640-4f19-4b28-973d-729602b5a4a7",
"model": "openai/gpt-5.5",
"num_messages": 58,
"duration_seconds": 617.32,
"task": "inspect_evals/osworld_small",
"app": "libreoffice_calc"
}
A failed score is still a valid eval result when Inspect completed and the
OSWorld scorer returned 0.0. Treat provider errors differently: those
indicate setup, Docker, model SDK, timeout, Inspect tool execution, or log
parsing failures before a scored sample was produced.
On subprocess failures, the wrapper keeps Promptfoo results compact: it returns a concise error and stores the local log path/status/duration, but it does not copy captured Inspect stdout or stderr into result metadata. Use the local Inspect logs for detailed screenshots, tool output, and trajectory debugging.
Inspect the exported Promptfoo JSON first:
jq '.results.results[] | {
success,
score,
error,
metadata: .response.metadata,
tokenUsage: .response.tokenUsage
}' osworld-results.json
For a benchmark report, separate scored rows from provider errors before you compute a pass rate:
jq '[.results.results[] | select((.response.metadata.status // "") != "error")] | length' \
osworld-full-results.json
jq -r '.results.results[]
| select((.response.metadata.status // "") == "error")
| [.vars.app, .vars.sample_id, .response.error]
| @tsv' osworld-full-results.json
Then dump the underlying Inspect log for the row you care about:
inspect log dump "$(jq -r '.results.results[0].response.metadata.inspect_log_path' osworld-results.json)" \
> inspect-log.json
jq '{
status,
sample_id: .samples[0].id,
score: .samples[0].scores.osworld_scorer.value,
final_answer: .samples[0].output.completion,
model_usage: .stats.model_usage
}' inspect-log.json
For benchmark reporting, rerun provider-error samples by exact sample_id with
--max-concurrency 1 before publishing a pass rate. If the rerun produces a
score, count it as a normal pass or fail. If it errors again, inspect the
.eval log and report it separately from scored OSWorld failures.
Reference GPT-5.5 run
As a larger smoke test, we ran all 21 osworld_small samples with exact
sample_id selectors, GPT-5.5, Promptfoo tracing enabled, and
--max-concurrency 6. The concurrent run produced one unscored Inspect
computer-tool runtime error. Rerunning that exact sample alone produced a normal
score of 0.0, so the final report below treats it as a scored failure rather
than an infrastructure error.
This is not a stable leaderboard number; it is a concrete example of the shape, cost, and follow-up workflow for a real run on one local machine.
For a comparable run, use the checked-in Python loader, keep the same provider
and defaultTest assertion block, and export the results:
PROMPTFOO_ENABLE_OTEL=true OTEL_EXPORTER_OTLP_ENDPOINT=http://127.0.0.1:4318 \
promptfoo eval -c promptfooconfig.yaml --no-cache --max-concurrency 6 \
-o osworld-small-results.json
| Metric | Result |
|---|---|
| Eval id | eval-7hQ-2026-04-28T02:52:18 |
| Error rerun eval id | eval-3rI-2026-04-28T03:30:43 |
| Samples | 21 |
| Concurrency | 6 |
| Wall time | 20m 9s |
| Passed | 13 / 21 |
| Scored failures after rerun | 8 / 21 |
| Provider errors after rerun | 0 / 21 |
| Mean OSWorld score | 0.665 |
| Promptfoo trace records | 21 |
| Promptfoo Python provider spans | 21 |
| Total token counter after rerun | 3,806,976 |
The strongest app clusters in that run were gimp and libreoffice_calc
at 100% pass rate. vscode passed 2 of 3. The hardest cases were mixed
desktop workflows, one OS administration task, the VLC conversion task, and one
near-miss LibreOffice Writer task that scored 0.9615 but did not meet the
strict score >= 1.0 assertion.
| App | Samples | Passed | Scored failures | Mean score |
|---|---|---|---|---|
gimp | 2 | 2 | 0 | 1.000 |
libreoffice_calc | 3 | 3 | 0 | 1.000 |
libreoffice_impress | 2 | 1 | 1 | 0.500 |
libreoffice_writer | 2 | 1 | 1 | 0.981 |
multi_apps | 6 | 3 | 3 | 0.500 |
os | 2 | 1 | 1 | 0.500 |
vlc | 1 | 0 | 1 | 0.000 |
vscode | 3 | 2 | 1 | 0.667 |
The rerun target was multi_apps sample
eb303e01-261e-4972-8c07-c9b4e7a4922a, a task that asks the agent to insert
speaker notes into a PowerPoint file. The original concurrent attempt errored
inside Inspect's computer tool while executing a model-requested desktop
command. The isolated rerun completed in 7m 44s, used 288,447 total tokens,
returned final answer DONE, and failed only because the OSWorld scorer
reported compare_pptx_files(...) returned 0.
Reference full-corpus GPT-5.5 run
We also ran the dedicated full-suite config against every Inspect-supported full-corpus sample in the installed version:
promptfoo eval -c promptfooconfig.full.yaml --no-cache --max-concurrency 3 \
-o osworld-full-results.json
The reference machine exposed a 6-vCPU, 16-GiB Colima VM to Docker, so
--max-concurrency 3 kept three desktop sandboxes active without pushing the VM
to saturation. Use the Docker VM's CPU and memory limits as the sizing input;
the host machine can have much more capacity than the desktop sandboxes can
actually use.
The raw run completed all 246 selected rows on April 30, 2026 in 5h27m5s and
used 54,421,072 total tokens. It produced 138 passes, 101 scored failures, and
7 provider errors. After rerunning those seven rows sequentially with
--max-concurrency 1, three became normal scored outcomes: one pass and two
failures. Four reproduced as provider errors, so the reconciled result is:
| Metric | Result |
|---|---|
| Samples | 246 |
| Scored rows after reruns | 242 |
| Passed | 139 |
| Scored failures after reruns | 103 |
| Provider errors after reruns | 4 |
| Pass rate over scored rows | 57.4% |
| Mean OSWorld score | 0.594 |
| Main-run wall time | 5h27m5s |
| Main-run token counter | 54,421,072 |
| Targeted rerun token counter | 1,917,890 |
The repeated provider errors were useful diagnostic evidence, not failed benchmark attempts:
- one
libreoffice_impressrow repeated an Inspect computer-tool runtime error - one
multi_appsrow repeated an OSWorld scorer missing-image-artifact error - two
vlcrows repeated an OSWorld scorer desktop-environment error
This is why the guide treats provider errors separately from scored OSWorld failures. Publish the raw run, the rerun policy, and the reconciled scored denominator together.
The app breakdown also changes what you learn from the run. GPT-5.5 was stronger
on focused spreadsheet and document edits than on multi-app workflows, and the
vlc group combined lower scores with two repeated harness-side failures. A
single aggregate pass rate would hide both patterns.
| App | Samples | Passed | Scored failures | Provider errors | Mean score |
|---|---|---|---|---|---|
gimp | 26 | 14 | 12 | 0 | 0.538 |
libreoffice_calc | 47 | 34 | 13 | 0 | 0.723 |
libreoffice_impress | 46 | 26 | 19 | 1 | 0.599 |
libreoffice_writer | 23 | 17 | 6 | 0 | 0.750 |
multi_apps | 46 | 17 | 28 | 1 | 0.435 |
os | 19 | 9 | 10 | 0 | 0.474 |
vlc | 16 | 6 | 8 | 2 | 0.491 |
vscode | 23 | 16 | 7 | 0 | 0.696 |
Inspect logs
Use Inspect logs for trajectory debugging:
inspect view --log-dir inspect_logs
The viewer shows screenshots, intermediate model messages, tool calls, files, scorer output, and token usage. The .eval files can contain sensitive screenshots and model outputs, so keep them out of git and avoid sharing them publicly.
Tracing
The example config starts Promptfoo's local OTLP receiver and passes a W3C
traceparent into the Python provider. Set PROMPTFOO_ENABLE_OTEL=true so the
Python provider wrapper records a child span with the prompt, response, token
usage, status, eval id, and test case id.
Trace-level visibility into OSWorld itself still lives in Inspect: every run
writes a .eval log, and inspect view displays the desktop trajectory.
Promptfoo receives one provider span per sample plus result metadata: output
text, score, token usage, sample id, status, and inspect_log_path.
You can verify that Promptfoo stored provider spans by checking the result's trace in the Promptfoo UI, or by asserting on raw spans in a separate trace-focused config. The real desktop trajectory remains in Inspect unless you build a bridge from Inspect events to OpenTelemetry spans.
To make the desktop actions Promptfoo-native tracing, the wrapper would need to
translate Inspect events into OpenTelemetry spans or expose a Promptfoo trace
object. Without that bridge, Promptfoo trace assertions such as
trajectory:tool-used cannot see the OSWorld mouse, keyboard, or screenshot
steps.
Reimplementation checklist
To reimplement the wrapper in another repo:
- Create a Promptfoo file provider with
call_api(prompt, options, context). - Put shared assertions and trace metadata in
defaultTest, then load generated rows withtests: file://osworld_tests.py:generate_tests. - Read
vars.sample_idfor exact runs, and keepvars.appfor filtering and result grouping. - Resolve
basePath,logRoot, and--log-dirto absolute paths before invoking Inspect. - Run
inspect eval inspect_evals/osworld_small --model <model> --sample-id <id> --log-dir <dir>for exact samples. - Run
inspect log dump <file.eval>and requiresamples[0].scores.osworld_scorer.valuefor the selected sample. Treat missing per-sample scorer output as a provider error instead of falling back to aggregate metrics. - Return Promptfoo
output,metadata.score,metadata.status,metadata.sample_id,metadata.inspect_log_path, andtokenUsage. - Make assertion pass/fail depend on the OSWorld score, not the provider's final text.
- Keep Inspect
.evallogs out of git and inspect them when scores or provider errors look surprising.
When to use this pattern
Use this wrapper when you want to:
- Run a real OSWorld desktop task from promptfoo.
- Compare models on a small number of expensive computer-use samples.
- Store benchmark scores beside other Promptfoo evals.
- Use Inspect's viewer for detailed trajectory review.
- Add Promptfoo assertions or CI gates around Inspect's scorer output.
Avoid treating this as a cheap smoke test. OSWorld samples are slow, stateful, and token-heavy. Start with one app or one exact sample_id, inspect the .eval log, then expand the sample set once the model and environment are stable.