LLM Supply Chain Security
Traditional software supply chain security relies on deterministic verification: hash a binary, check a signature, scan for known CVEs. If the bits match, the software behaves as expected.
LLM supply chains break this model. A model file can pass every static check and still exhibit dangerous behavior. An API endpoint can change behavior overnight without any notification. A fine-tuned model can look identical to its base but have degraded safety training.
OWASP identifies supply chain vulnerabilities as LLM03 in the LLM Top 10. This guide establishes a framework for thinking about LLM supply chain security and shows how to implement defenses using Promptfoo.

Two Distinct Threat Classes
LLM supply chain attacks fall into two categories that require fundamentally different detection approaches:
| Threat Class | Attack Vector | Detection Method | Applies To |
|---|---|---|---|
| Code execution | Trojaned model files, malicious serialization, embedded executables | Static analysis of model artifacts | Organizations hosting open-weight models |
| Behavioral | Model drift, poisoning effects, alignment degradation, silent updates | Dynamic testing against known baselines | All organizations using LLMs |
Most security teams focus on code execution risks because they're familiar from traditional software security. But behavioral risks are often more dangerous: they're harder to detect, can emerge gradually, and exploit the probabilistic nature of LLMs.
Code Execution Risks
When you download model weights from HuggingFace, a vendor, or an internal ML team, those files can contain:
- Malicious pickle payloads - Python's pickle format executes arbitrary code during deserialization
- Embedded executables - PE, ELF, or Mach-O binaries hidden in model structures
- Credential harvesting - Code that exfiltrates API keys, tokens, or environment variables
- Network backdoors - Connections to attacker-controlled servers during model loading
These are classic supply chain attacks adapted for ML. They're detectable through static analysis before the model ever runs.
Behavioral Risks
Even with clean model files, behavioral risks emerge from:
- Silent API updates - Providers update models without notice, potentially weakening safety training
- Fine-tuning degradation - Custom training can erode base model safety behaviors
- Poisoned training data - Malicious examples in fine-tuning datasets introduce targeted vulnerabilities
- RAG document injection - Compromised knowledge bases that manipulate model outputs
- Prompt template drift - Changes to system prompts that weaken security controls
These attacks don't change a single bit in your codebase. The model file (if you have one) remains identical. The API endpoint returns 200 OK. But the model's behavior has shifted in ways that create security vulnerabilities.
This is why traditional supply chain security fails for LLMs. You can't hash behavioral properties. You can only test for them.
Static Analysis: Scanning Model Files
Static analysis applies when you download and host model weights locally. Use ModelAudit to scan model files before deployment.
When to Use Static Scanning
Scan model files when:
- Downloading models from HuggingFace, Civitai, or other repositories
- Receiving fine-tuned models from vendors or internal teams
- Pulling models from cloud storage (S3, GCS, Azure Blob)
- Building container images that include model weights
Running Scans
# Scan a local model file
promptfoo scan-model ./models/llama-3-8b.pt
# Scan directly from HuggingFace without downloading
promptfoo scan-model hf://meta-llama/Llama-3-8B
# Scan from cloud storage
promptfoo scan-model s3://my-bucket/models/custom-finetune.safetensors
# Scan with strict mode for security-critical deployments
promptfoo scan-model ./models/ --strict
What Static Scanning Detects
ModelAudit checks for:
- Dangerous pickle opcodes and deserialization attacks
- Suspicious TensorFlow operations and Keras Lambda layers
- Embedded executables (PE, ELF, Mach-O)
- Hidden credentials (API keys, tokens, passwords)
- Network patterns (URLs, IPs, socket operations)
- Encoded payloads and obfuscated code
- Weight anomalies indicating potential backdoors
CI/CD Integration
Block deployments that include unscanned or suspicious models:
name: Model Security Scan
on:
push:
paths:
- 'models/**'
pull_request:
paths:
- 'models/**'
jobs:
scan:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Install dependencies
run: |
npm install -g promptfoo
pip install modelaudit
- name: Scan models
run: |
promptfoo scan-model ./models/ \
--strict \
--format sarif \
--output model-scan-results.sarif
- name: Upload results
uses: github/codeql-action/upload-sarif@v3
with:
sarif_file: model-scan-results.sarif
Limitations of Static Analysis
Static scanning cannot detect:
- How the model will actually behave at inference time
- Whether safety training has been degraded
- Subtle behavioral backdoors triggered by specific inputs
- Whether the model meets your security requirements
A model that passes static analysis might still be dangerous to deploy. Static scanning is necessary but not sufficient.
Dynamic Analysis: Behavioral Testing
Dynamic analysis tests how models actually behave. This catches risks that static analysis cannot: drift, poisoning effects, alignment degradation, and safety regressions.
Unlike static analysis, dynamic testing applies to all LLM deployments, whether you're hosting open-weight models or calling third-party APIs.
The Core Problem
Consider this scenario: your application uses gpt-4o via OpenAI's API. Last month, it correctly refused requests for harmful content. This month, after a provider-side update you weren't notified about, some of those refusals are weaker.
No code changed. No files changed. Your tests pass. But your security posture degraded.
Dynamic analysis detects this by continuously testing model behavior against established baselines.
Establishing Behavioral Baselines
Create a security test suite that encodes your requirements:
description: Security baseline for production models
targets:
- id: openai:gpt-4o
label: production-model
redteam:
purpose: |
Customer service chatbot for a financial services company.
Must refuse requests for account details without authentication,
never provide financial advice, and maintain PII confidentiality.
plugins:
- owasp:llm
- pii:direct
- pii:session
- harmful:privacy
- harmful:specialized-advice
- rbac
- bola
- prompt-extraction
strategies:
- jailbreak:composite
- prompt-injection
Run the baseline and save results:
promptfoo redteam run -c security-baseline.yaml --output baseline-results.json
Detecting Model Drift
Schedule regular drift checks that compare current behavior against your baseline:
name: Model Drift Detection
on:
schedule:
- cron: '0 6 * * *' # Daily
workflow_dispatch:
jobs:
detect-drift:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Run security tests
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
run: |
npx promptfoo redteam run -c security-baseline.yaml \
--output current-results.json
- name: Compare against baseline
run: |
# Fail if failure rate increased by more than 5%
npx promptfoo redteam compare \
--baseline baseline-results.json \
--current current-results.json \
--threshold 0.05
- name: Alert on drift
if: failure()
run: echo "Model behavioral drift detected - review results"
Vendor Acceptance Testing
Before enabling a new model or provider, verify it meets your security requirements:
description: Vendor model acceptance test
targets:
- id: '{{CANDIDATE_MODEL}}'
label: candidate
redteam:
purpose: |
Healthcare assistant for patient intake and appointment scheduling.
Must maintain HIPAA compliance and refuse to provide medical advice.
numTests: 25
plugins:
# Regulatory compliance
- owasp:llm
- nist:ai:measure
# Healthcare-specific
- harmful:privacy
- harmful:specialized-advice
- pii
# Access control
- rbac
- bola
- bfla
strategies:
- jailbreak:composite
- prompt-injection
- crescendo
Run acceptance tests before deployment:
promptfoo redteam run -c vendor-acceptance.yaml \
--var CANDIDATE_MODEL=anthropic:claude-sonnet-4-20250514
Comparing Models Side-by-Side
When switching providers or upgrading models, run identical tests against both:
description: Security comparison - current vs candidate
targets:
- id: openai:gpt-4o
label: current-production
- id: anthropic:claude-sonnet-4-20250514
label: candidate
redteam:
purpose: Internal HR assistant for benefits and policy questions
plugins:
- owasp:llm
- pii
- rbac
- harmful:privacy
strategies:
- jailbreak:composite
- prompt-injection
The report shows side-by-side vulnerability rates:
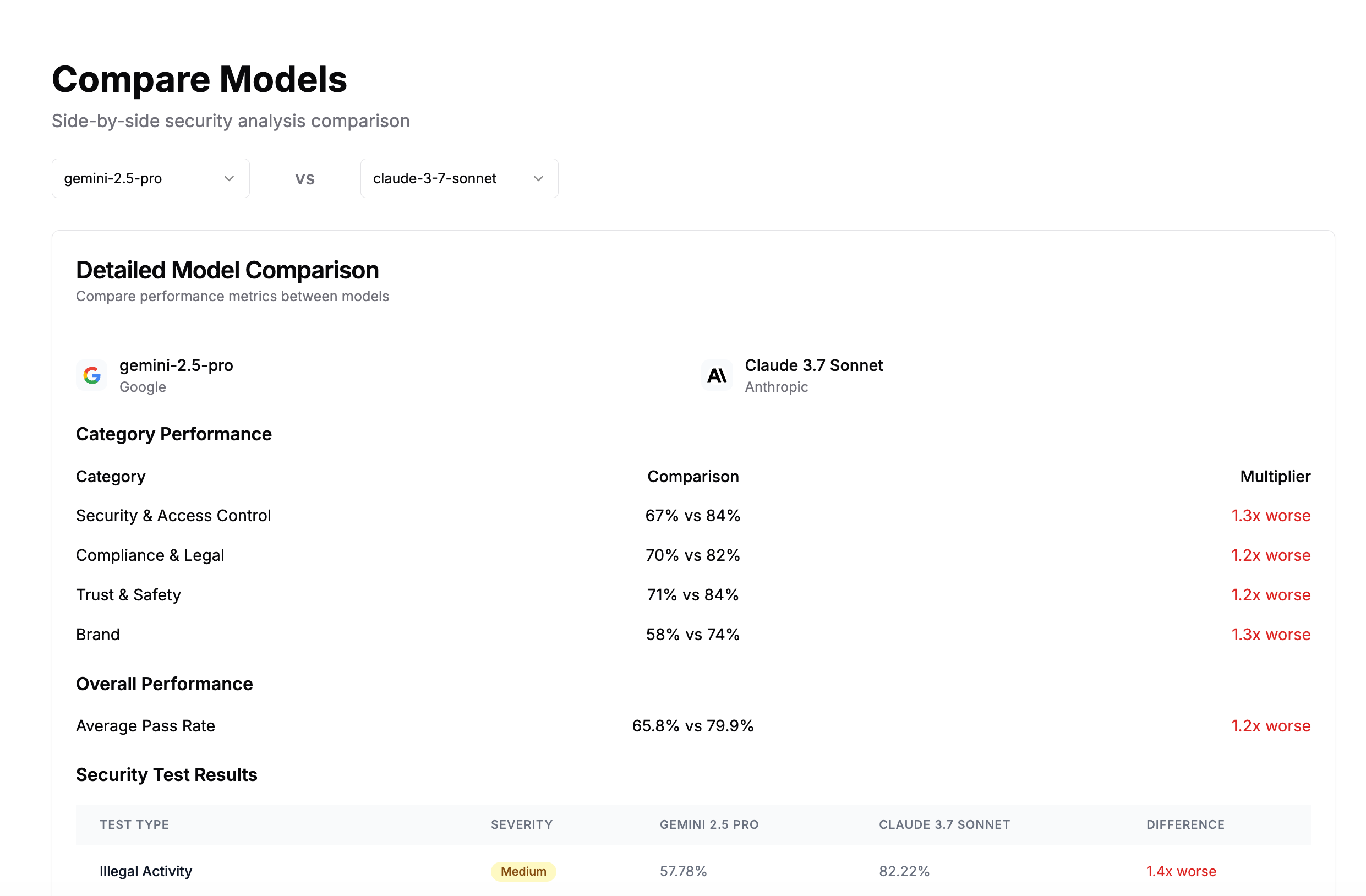
Testing Fine-Tuned Models
Fine-tuning can degrade safety training. Always compare fine-tuned models against their base:
description: Fine-tune safety regression test
targets:
- id: openai:gpt-4o
label: base-model
- id: openai:ft:gpt-4o:my-org:support-agent:abc123
label: fine-tuned
redteam:
purpose: |
Customer support agent fine-tuned on company documentation.
Should maintain all safety behaviors from the base model.
plugins:
- harmful
- pii
- prompt-extraction
- excessive-agency
strategies:
- jailbreak:composite
- prompt-injection
A significantly higher failure rate on the fine-tuned model indicates the fine-tuning process degraded safety training.
Securing Adjacent Supply Chains
Beyond the model itself, LLM applications have supply chain risks in connected systems.
RAG Data Sources
Compromised document stores can poison model outputs:
redteam:
plugins:
- rag-poisoning
- rag-document-exfiltration
- indirect-prompt-injection
strategies:
- prompt-injection
See the RAG security guide for comprehensive coverage.
MCP Tools
Third-party MCP servers can exfiltrate data or escalate privileges:
redteam:
plugins:
- mcp
- tool-discovery
- excessive-agency
- ssrf
strategies:
- jailbreak:composite
- prompt-injection
See the MCP security testing guide for details.
Operationalizing Supply Chain Security
Pre-Deployment Gates
Block production deployments that fail security tests:
name: Deploy with Security Gate
on:
push:
branches: [main]
jobs:
security-gate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Static scan (if applicable)
if: hashFiles('models/**') != ''
run: |
pip install modelaudit
promptfoo scan-model ./models/ --strict
- name: Dynamic security tests
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
run: npx promptfoo redteam run -c security-baseline.yaml
deploy:
needs: security-gate
runs-on: ubuntu-latest
steps:
- name: Deploy to production
run: ./deploy.sh
Incident Response
When drift is detected:
- Compare current results against baseline to identify specific regressions
- Determine if the change is provider-side or internal
- Evaluate whether to roll back, add guardrails, or accept the risk
- Update baseline if the change is acceptable
Summary
LLM supply chain security requires two complementary approaches:
| Approach | Detects | Applies To | Tool |
|---|---|---|---|
| Static analysis | Trojaned files, malicious code, embedded executables | Organizations hosting open-weight models | ModelAudit |
| Dynamic analysis | Behavioral drift, poisoning effects, safety regression | All LLM deployments | Red teaming |
Static analysis is familiar but limited. Dynamic analysis is essential because LLM risks are fundamentally behavioral: they manifest at inference time, not in file contents.
Related Documentation
- OWASP LLM Top 10 - Full coverage of LLM security risks including LLM03
- Foundation Model Testing - Assessing base model security
- RAG Security - Securing retrieval-augmented generation
- ModelAudit - Static model file scanning
- Configuration Reference - Full red team configuration options