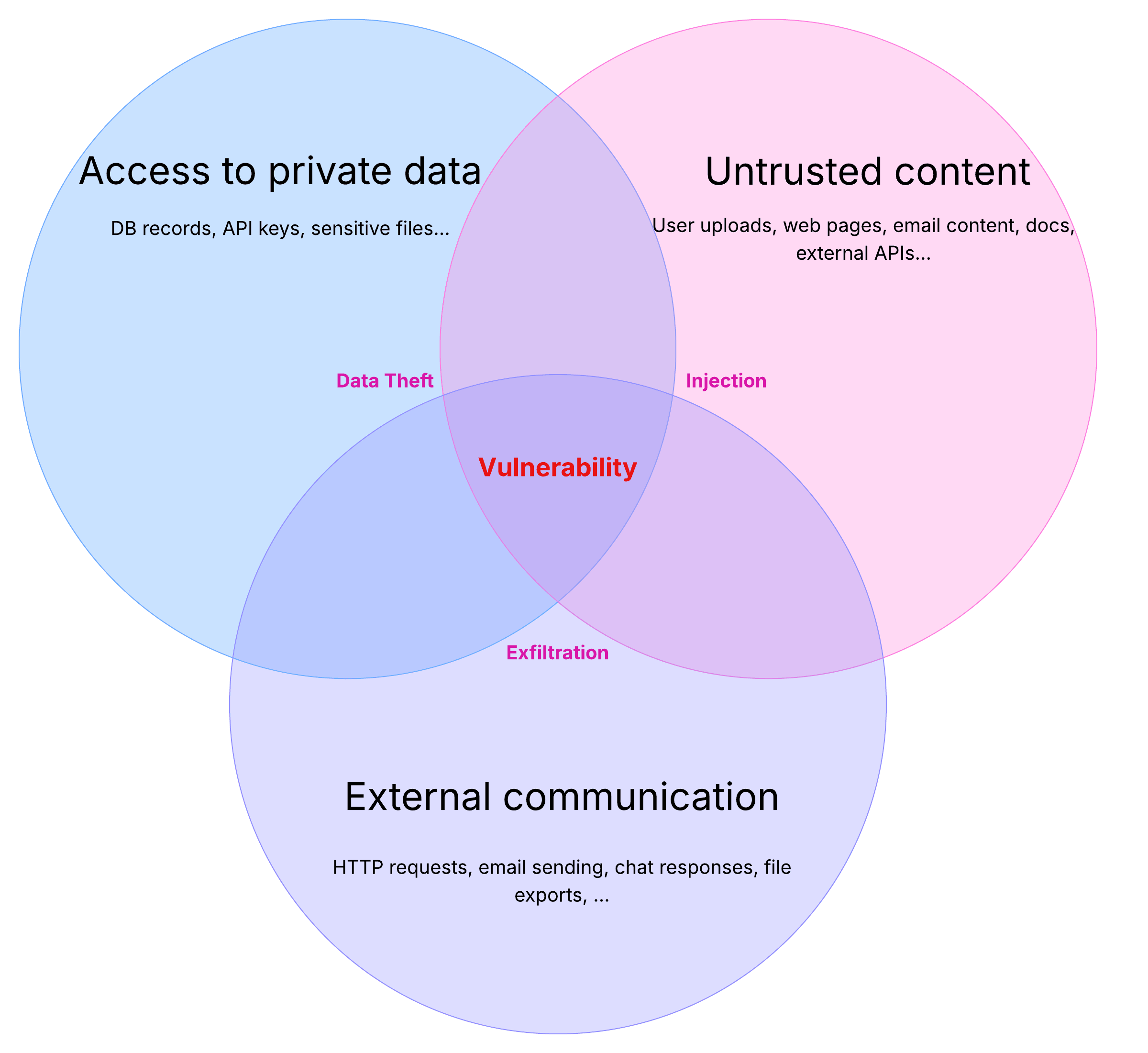
GPT-5.2 Initial Trust and Safety Assessment

OpenAI released GPT-5.2 today (December 11, 2025) at approximately 10:00 AM PST. We opened a PR for GPT-5.2 support at 10:24 AM PST and kicked off a red team eval (security testing where you try to break something). First critical finding hit at 10:29 AM PST, 5 minutes later. This is an early, targeted assessment focused on jailbreak resilience and harmful content, not a full security review.
This post covers what we tested, what failed, and what you should do about it.
The headline numbers: our jailbreak strategies (techniques that trick AI into bypassing its safety rules) improved attack success from 4.3% baseline to 78.5% (multi-turn) and 61.0% (single-turn). The weakest categories included impersonation, graphic and sexual content, harassment, disinformation, hate speech, and self-harm, where a majority of targeted attacks succeeded.