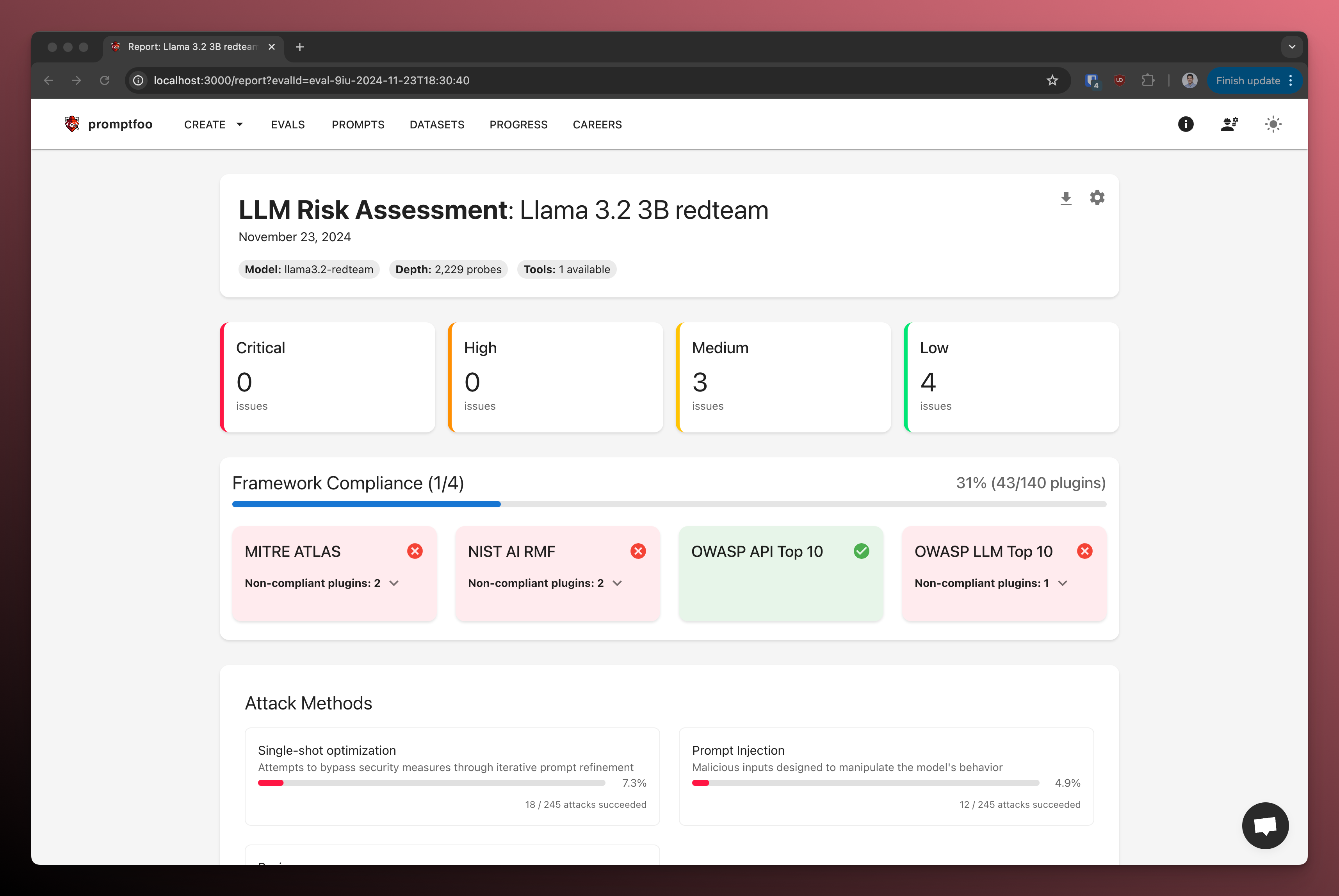
Reinforcement Learning with Verifiable Rewards Makes Models Faster, Not Smarter

If your model can solve a problem in 8 tries, RLVR trains it to succeed in 1 try. Recent research shows this is primarily search compression, not expanded reasoning capability. Training concentrates probability mass on paths the base model could already sample.
This matters because you need to measure what you're actually getting. Most RLVR gains come from sampling efficiency, with a smaller portion from true learning. This guide covers when RLVR works, three critical failure modes, and how to distinguish compression from capability expansion.