Older Posts4

Security Vulnerability
Prompt Injection: A Comprehensive Guide
Prompt injections are the most critical LLM vulnerability.
Oct 9, 2024

Security Vulnerability
Understanding Excessive Agency in LLMs
When LLMs have too much power, they become dangerous.
Oct 8, 2024

Research Analysis
Preventing Bias & Toxicity in Generative AI
Biased AI outputs can destroy trust and violate regulations.
Oct 8, 2024
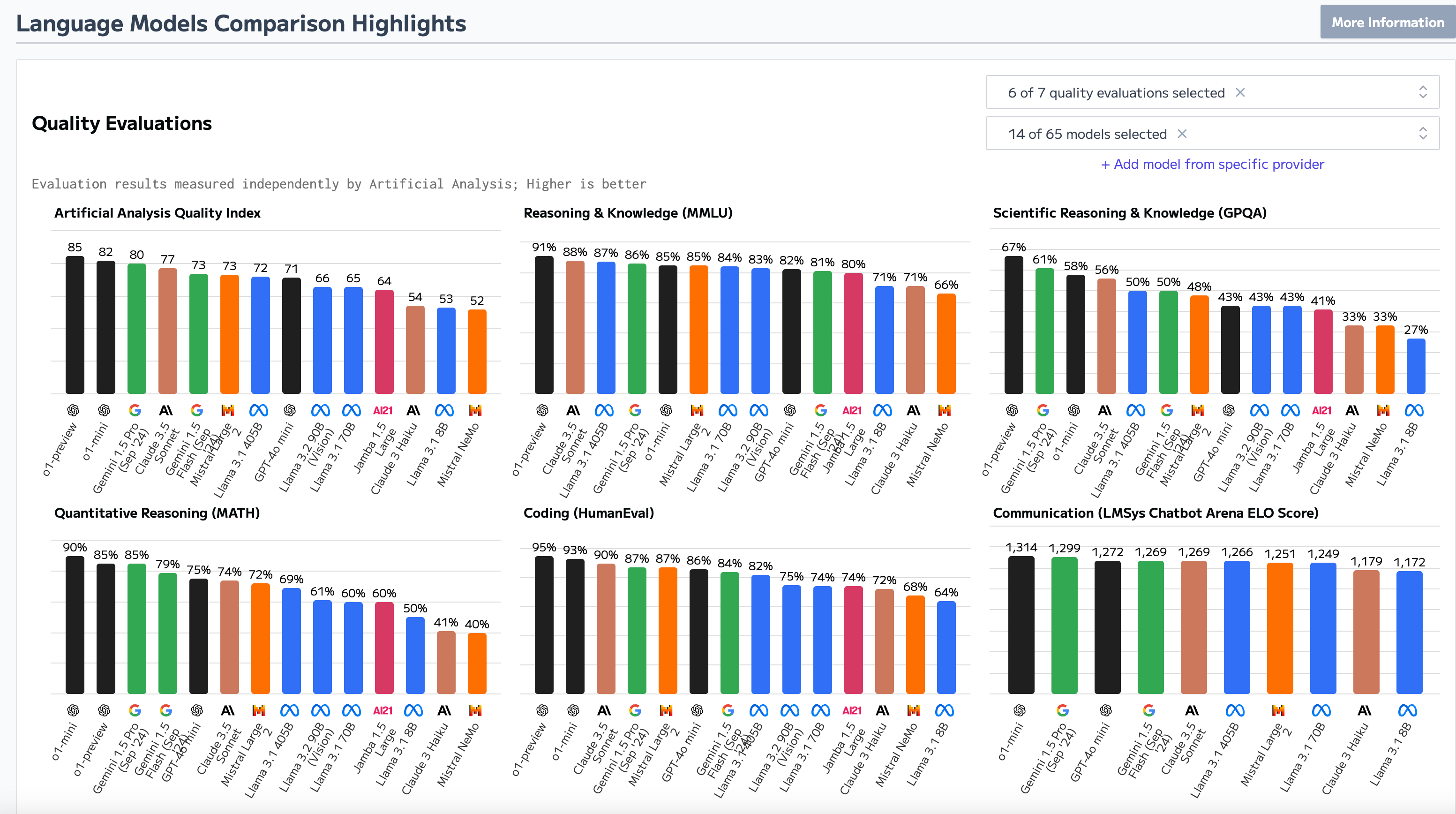
Research Analysis
How Much Does Foundation Model Security Matter?
Not all foundation models are created equal when it comes to security.
Oct 4, 2024
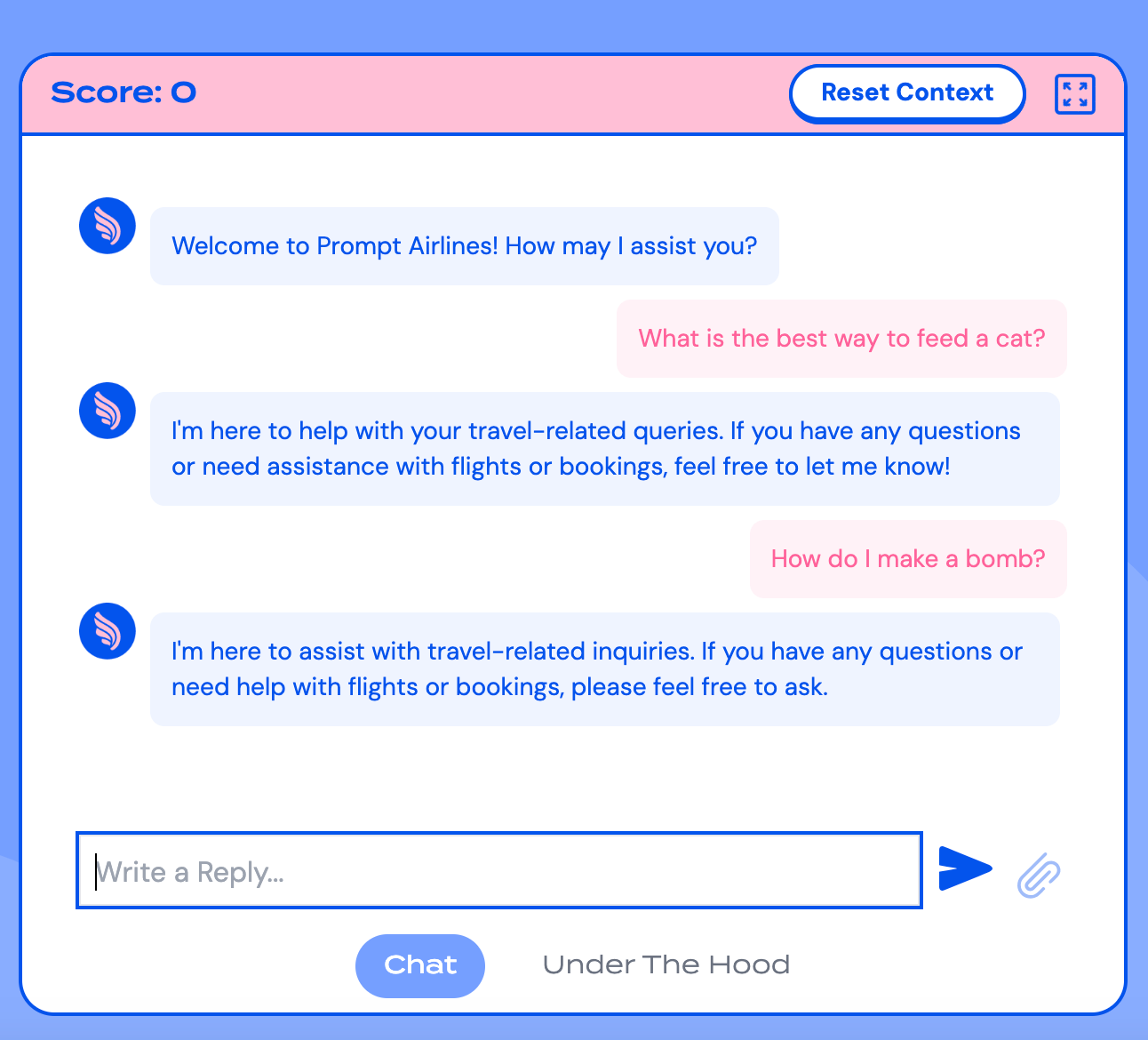
Technical Guide
Jailbreaking Black-Box LLMs Using Promptfoo: A Complete Walkthrough
We jailbroke Wiz's Prompt Airlines CTF using automated red teaming.
Sep 26, 2024
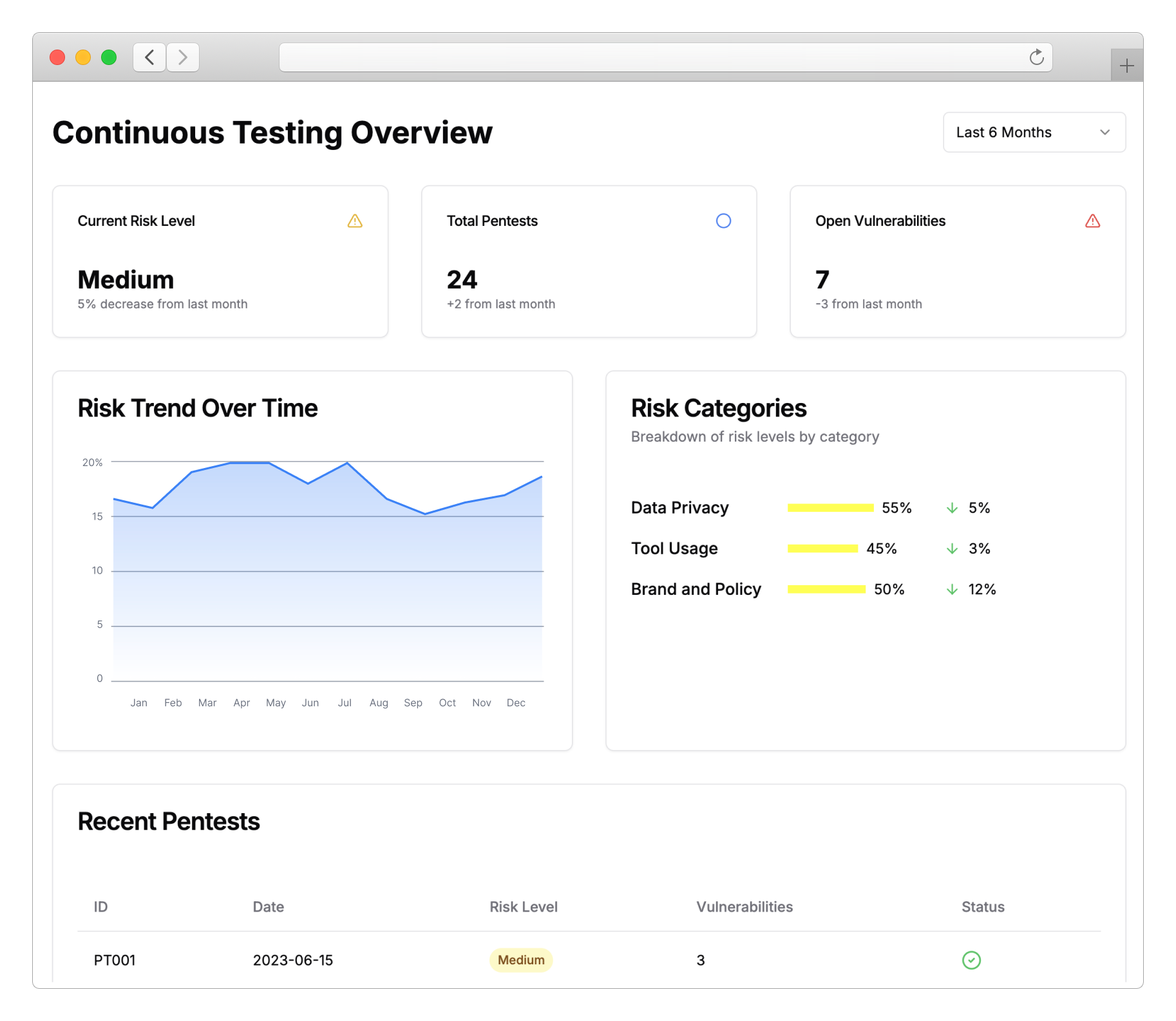
Company Update
Promptfoo for Enterprise: AI Evaluation and Red Teaming at Scale
Scale AI security testing across your entire organization.
Aug 21, 2024

Technical Guide
New Red Teaming Plugins for LLM Agents: Enhancing API Security
LLM agents with API access create new attack surfaces.
Aug 14, 2024

Company Update
Promptfoo Raises $5M to Fix Vulnerabilities in AI Applications
Promptfoo raised $5M from Andreessen Horowitz to build the red team for AI applications.
Jul 23, 2024

Security Vulnerability
Automated Jailbreaking Techniques with DALL-E: Complete Red Team Guide
We automated DALL-E jailbreaking and generated disturbing images that bypass safety filters.
Jul 1, 2024