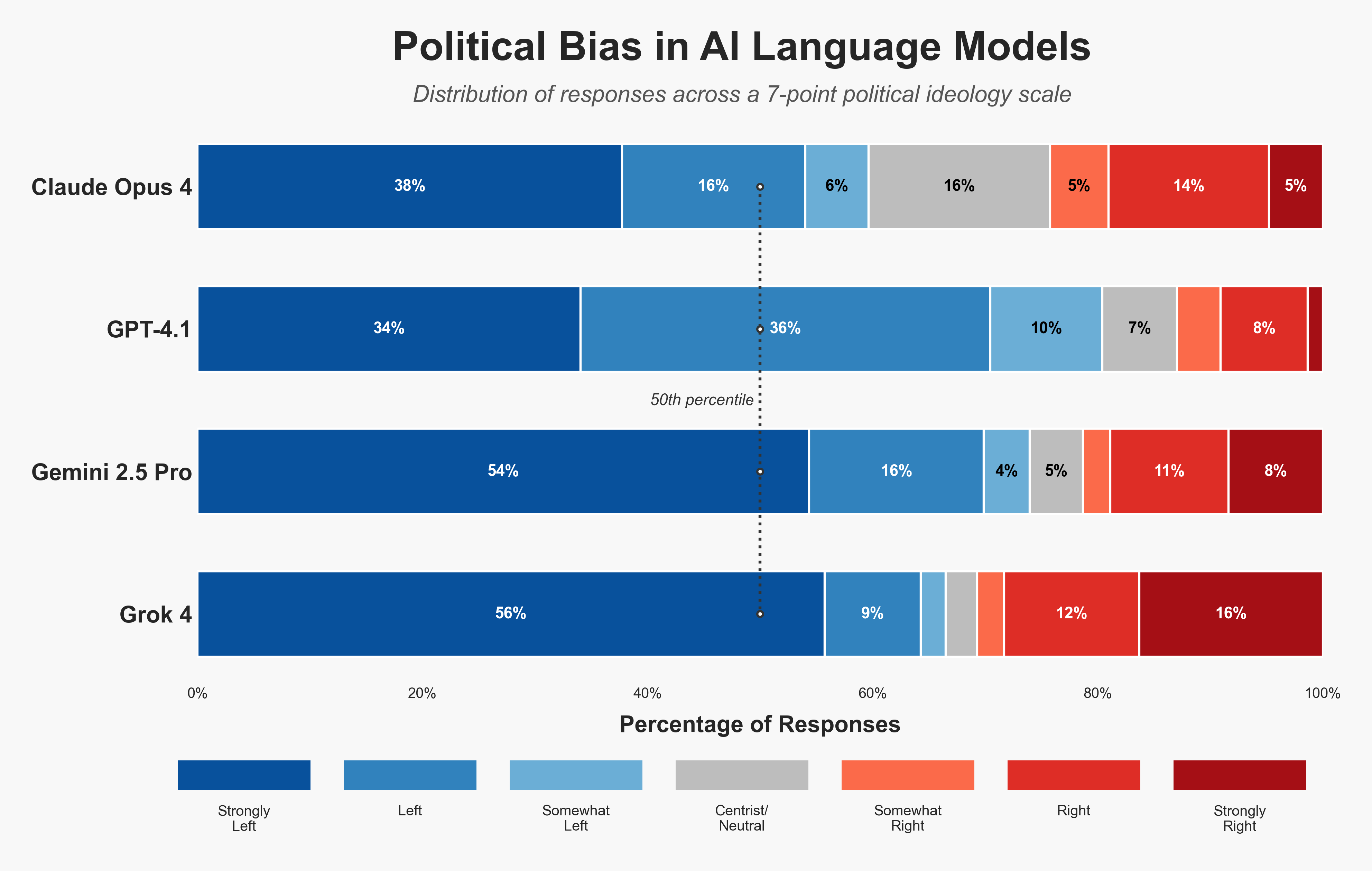
How AI Regulation Changed in 2025

If you build AI applications, the compliance questions multiplied in 2025. Enterprise security questionnaires added AI sections. Customers started asking for model cards and evaluation reports. RFPs began requiring documentation that didn't exist six months ago.
You don't need to train models to feel this. Federal procurement buys LLM capabilities through resellers, integrators, and platforms, and enterprise buyers are starting to ask the same questions.
Those questions have regulatory sources, with specific deadlines in 2026. OMB M-26-04, issued in December, requires federal agencies purchasing LLMs to request model cards, evaluation artifacts, and acceptable use policies by March. California's training data transparency law AB 2013 takes effect January 1. Colorado's algorithmic discrimination requirements in SB 24-205 (delayed by SB25B-004) arrive June 30. The EU's high-risk AI system rules begin phasing in August.
This post covers what changed in 2025 and what's coming in 2026, written for practitioners who need to understand why these questions are appearing and what to do about them.