Building a Security Scanner for LLM Apps

We're adding something new to Promptfoo's suite of AI security products: code scanning for LLM-related vulnerabilities. In this post, I will:
- Briefly introduce the new product
- Explain why we think engineering teams need a scanner focused exclusively on interactions with LLMs and agents
- Demonstrate the scanner in action on a few real-world CVEs (click here to skip the background and jump straight to real examples)
While we see this as eventually evolving into at least a few distinct tools based on the same underlying scanning engine, the first incarnation is a GitHub Action that automatically reviews every new pull request for security issues related to LLMs and agents. To do this, it uses its own security-focused AI agents to examine the PR, tracing into the larger repo as needed to understand how new code fits in.
If it finds any problems, it will comment on the specific lines of code that are concerning, explain the issue, and suggest a fix. It will also supply a prompt an engineer can send straight to an AI coding agent.
If it doesn't find anything, you'll get an emotionally satisfying 👍 All Clear, plus a quick summary of what the scanner looked at.
Focus matters
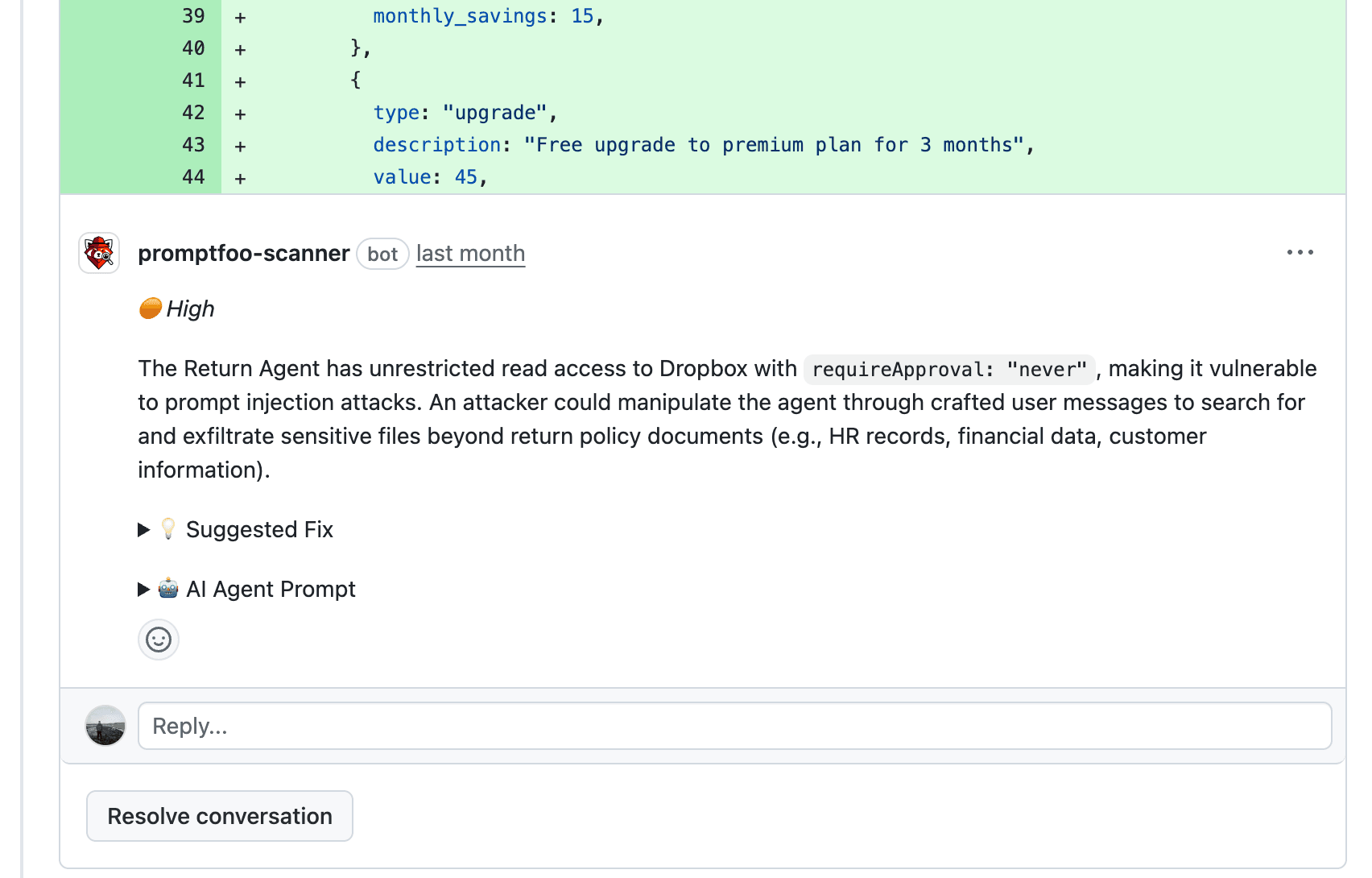
We've been using this scanner in our own repos for several weeks now, and it's already flagged some issues that might have slipped through otherwise. We use other automatic code review tools, and we also require that every PR is reviewed by a 100% human engineer. But in a number of the cases that the Promptfoo scanner has found an issue, it was the only reviewer, human or bot, which flagged that particular issue.
I think one reason for this is, in a single word: focus. Because the scanner has a single job to do, and is designed to find a small set of specific problematic patterns, it's more effective at finding those patterns than either a human or LLM that's doing a more general review.
Another reason is that an effective strategy for finding the most common and severe vulnerabilities in LLM apps definitely would not be an effective strategy for a general review tool, even a general security review tool.
What makes LLM apps different
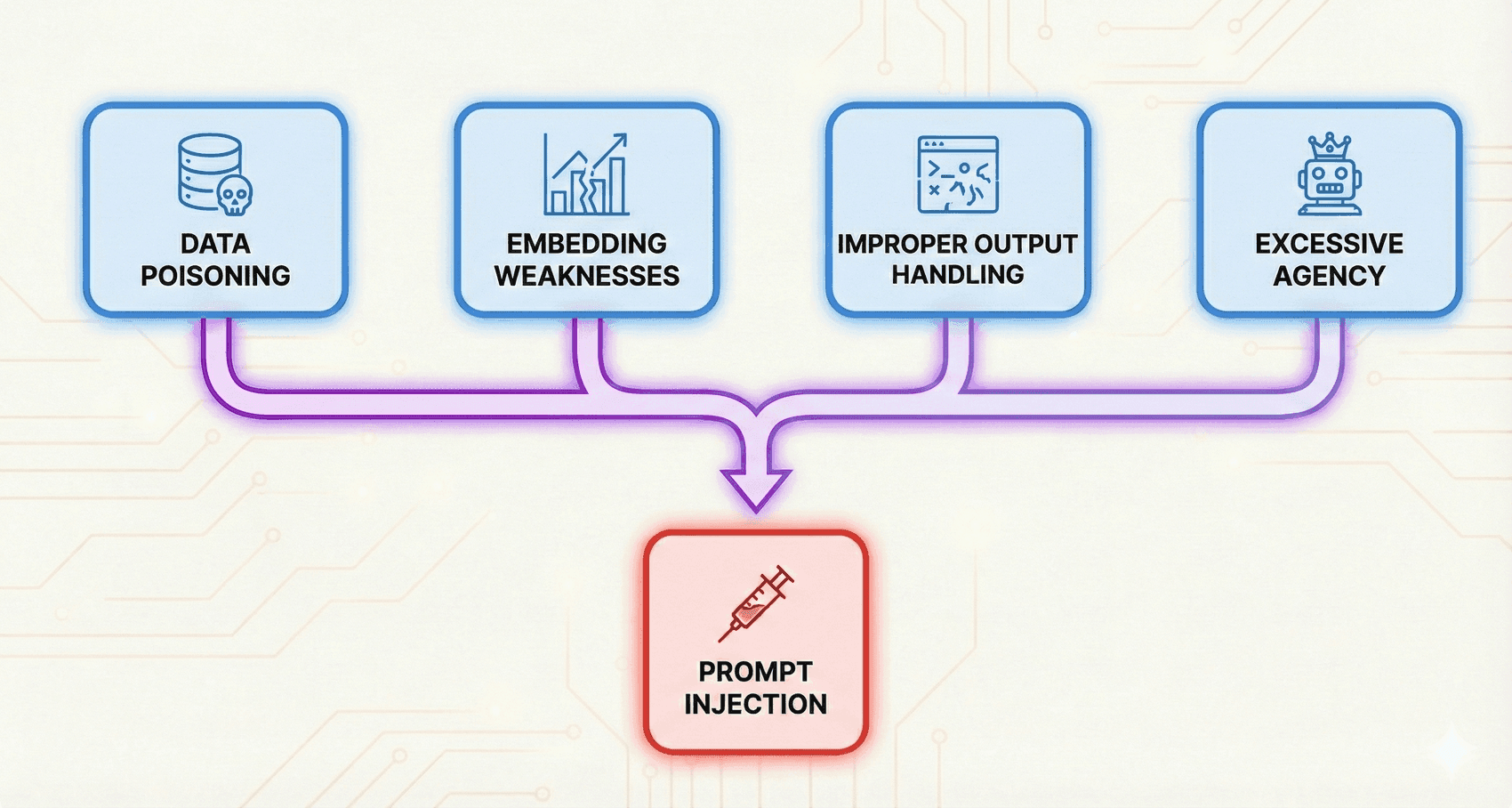
Let's get into why it's valuable to have a security scanner focused just on LLMs. I'd argue that the worst LLM vulnerabilities which are relevant to a code scanner fit into basically three categories:
- Sensitive information disclosure
- Jailbreak risk
- Prompt injection
There are a lot of more specific vulnerabilities (check out the OWASP top 10 for LLM Applications for examples), but most of these either:
- Fall under one of the three categories above.
- Data poisoning, embedding weaknesses, improper output handling, and excessive agency can all be viewed as vectors for prompt injection.
- System prompt leakage falls under both sensitive information disclosure and jailbreak risk.
- Are out of scope for code scanning.
- Supply chain vulnerabilities, model poisoning, and misinformation are problems in the model layer, not the code, though I should note that Promptfoo does also offer model scanning.
- Unbounded consumption is difficult to judge from the code alone, as it depends on implicit assumptions for what kind of token usage is acceptable. Also, model providers have their own
maxTokenslimits and rate limits.
Even sensitive information disclosure, which is a legitimate LLM-specific vulnerability class in its own right, is most concerning when it coincides with prompt injection or jailbreak risk. Disclosing sensitive information to an LLM provider, while not ideal, is typically not directly exploitable, and is often an intentional tradeoff that developers make for the sake of building a useful app.
So now I'd say that we can whittle the list down to two underlying areas of concern:
- Jailbreak risk
- Prompt injection
Jailbreak risk is definitely a major concern for LLM apps, but tends to have an interesting quality: it's bimodal in terms of how easy it is to detect.
It's either fairly obvious, as in cases where a developer tries to use the system prompt for authorization or access control instead of deterministic checks. Or it's quite difficult, as in cases where many different attack styles need to be tried, or complex conversation state needs to be built up before a jailbreak succeeds.
The obvious cases are definitely relevant to code scanning, and Promptfoo's code scanner certainly does look for them as it scans prompts. But exactly because they're obvious, they have less influence on the overall design of the scanner. As long as we are scanning prompts and identifying these kinds of issues, they will be flagged. Obvious jailbreak vectors are important to catch, but they aren't the hard part.
For the non-obvious cases, code scanning just isn't the right modality. You need red teaming to simulate a wide variety of attacks (often involving many steps and complex state).
That leaves prompt injection. The big kahuna. Nearly everything that can go terribly wrong in an LLM app from a security perspective is upstream of it, downstream of it, or somehow connected. It can also be very difficult to detect, and very easy for developers, including experienced, security-conscious developers, to accidentally introduce into an LLM-based system.
The lethal trifecta (and deadly duo)
Sadly, developers building apps on top of LLMs are constantly faced with an uncomfortable truth: there is a deep tension between making LLM apps secure and making them compelling and useful as products.
To understand why, I'm just going to quote directly from Simon Willison's famous post, The Lethal Trifecta.
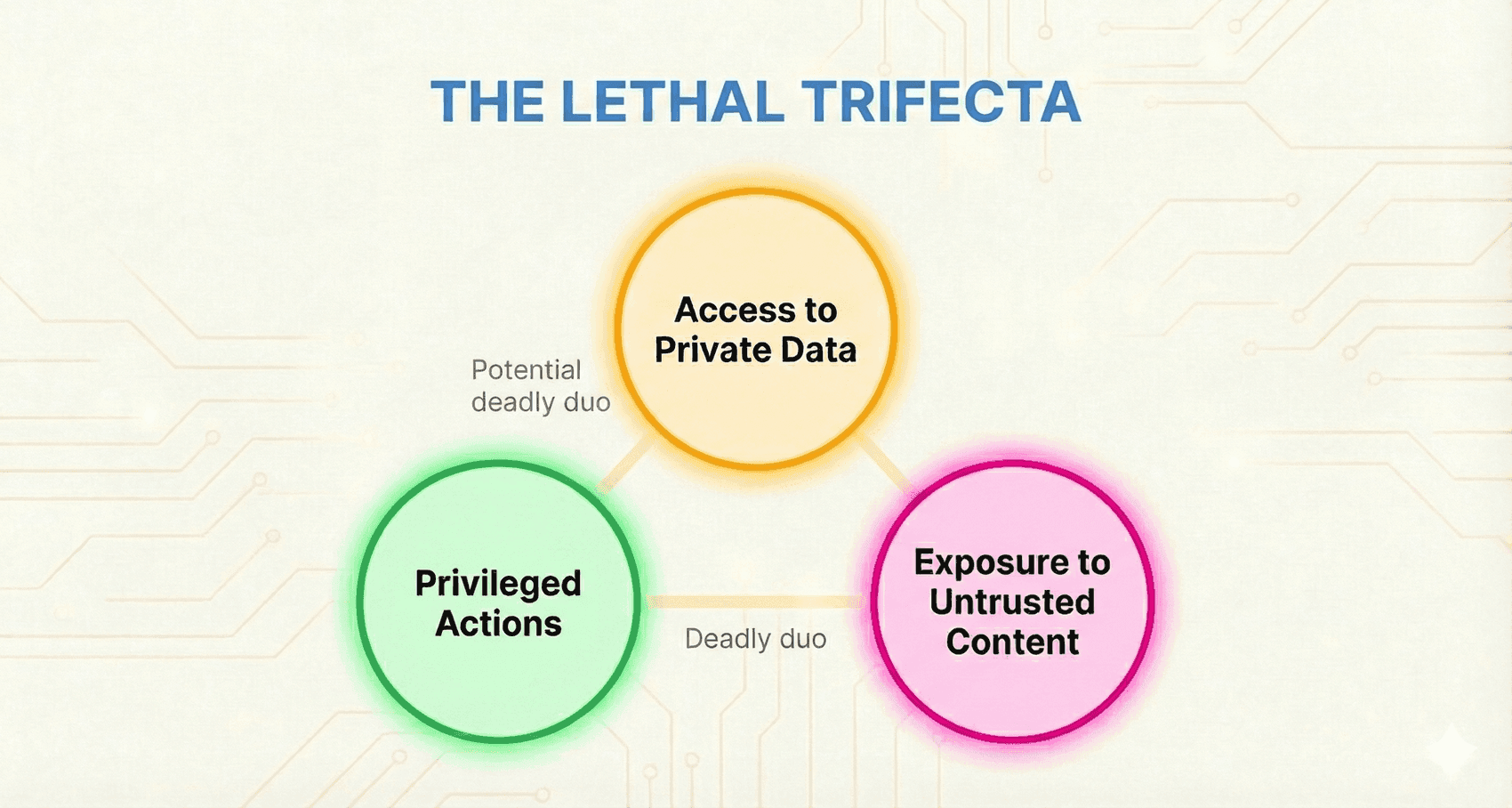
The lethal trifecta of capabilities is:
- Access to your private data—one of the most common purposes of tools in the first place!
- Exposure to untrusted content—any mechanism by which text (or images) controlled by a malicious attacker could become available to your LLM
- The ability to externally communicate in a way that could be used to steal your data
He then says:
If your agent combines these three features, an attacker can easily trick it into accessing your private data and sending it to that attacker.
Now think about the AI products you use regularly. Or go through a list of the last hundred AI startups to raise seed rounds. How many examples can you find that don't include all three of these, in some combination?
If an LLM app:
- Has access to private data (including user prompts themselves, ala ChatGPT or Claude Code)
- Can load random web pages (again, both ChatGPT and Claude Code can do this)
It already has the lethal trifecta, because loading web pages covers both "exposure to untrusted content" and "the ability to externally communicate" (arbitrary data can be passed through URL paths or query parameters).
We can also expand on "the ability to externally communicate". As Simon pointed out in another more recent post:
The one problem with the lethal trifecta is that it only covers the risk of data exfiltration: there are plenty of other, even nastier risks that arise from prompt injection attacks against LLM-powered agents with access to tools which the lethal trifecta doesn't cover.
The point being, that instead of just being capable of "communicating" and sending private data somewhere, agents with the right tools and permissions can make destructive SQL queries, compromise systems, empty crypto wallets, and a lot more. The label I'd use is privileged actions.
And what's more, you don't even need all three of these to have a problem. Just two can be enough to have an issue: a deadly duo, if you will. Exposure to untrusted content + privileged actions is enough to create a vulnerability even without access to private data. And access to private data + external communication or privileged actions can be enough to create a vulnerability if there's any gap in access control.
Laundering traditional injection vulnerabilities

If you have experience with traditional web app security, you're probably quite familiar with injection vulnerabilities. There are a lot of variations:
- SQL injection (aka Database Injection, since it doesn't only apply to SQL databases)
- Command injection (aka Shell Injection, one of the most dangerous)
- Script injection (aka XSS—cross-site scripting)
- Path injection (manipulating file paths)
- And many others
All these follow basically the same pattern.
- The app receives untrusted input.
- The app takes some privileged action (there's that term again) which includes the unsanitized input from step 1.
In SQL injection, step 2 is an SQL query. In command injection, it's a shell command. In XSS, it's rendering HTML in a browser.
Injection vulnerabilities are nasty, and they used to be extremely common. But fortunately, modern database libraries now have built-in protection against SQL injection, and web libraries have built-in protection against XSS. On top of that, awareness about injection vulnerabilities is generally high in the developer community, and addressing them is a fairly simple matter: you just need to sanitize the untrusted input before passing it to a privileged action. User input sent into SQL queries has any SQL keywords escaped. User input sent to a shell command is wrapped in single quotes. <script> tags are disallowed in user-submitted text. And so on.
That's not to say that injection vulnerabilities can't still crop up, but you'd generally have to be doing something a bit lower-level or atypical. If you're writing routine web app code with popular libraries, you'll avoid them without trying.
Prompt injection is different.
Though the flow is basically the same—you have untrusted input flowing into a privileged action—there's another step in the middle that fundamentally changes things. You guessed it: the LLM.
Why? Because the LLM "launders" the untrusted input into an output that looks and feels safe, but really isn't. And making matters worse, LLM responses aren't just "inputs" into database queries and shell commands. They are database queries and shell commands. And how do you "sanitize" a query or shell command when the entire thing is untrusted? Easy: you can't.
Call graphs and IO flows
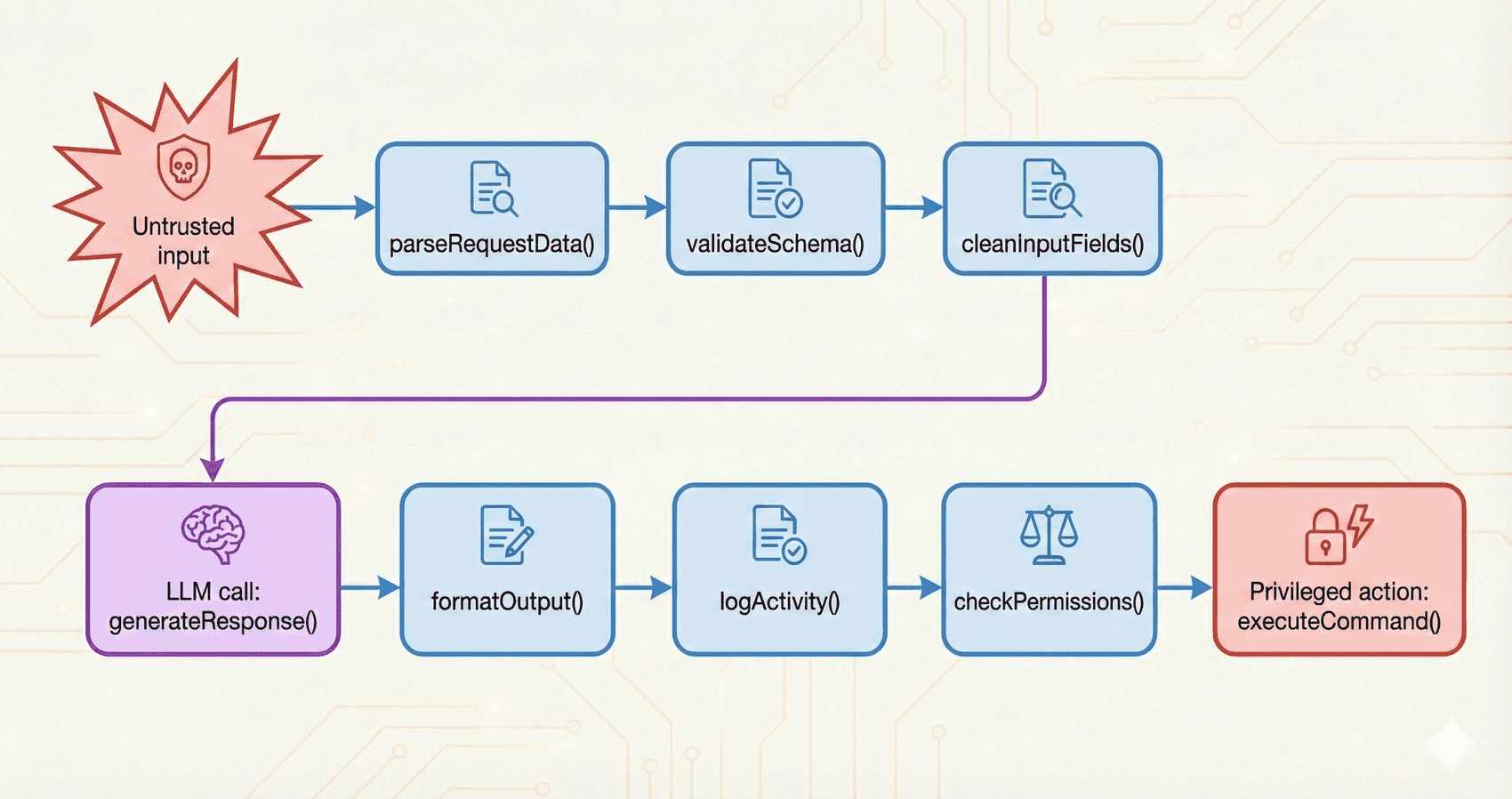
Because most serious LLM app vulnerabilities are injection vulnerabilities, catching them often requires tracing inputs and outputs exhaustively through the app. But because, as discussed in the previous section, we often can't rely on sanitization, the task is more difficult than for traditional injection vulnerabilities. General security scanners do trace, but they can take a shortcut: if any string is passed into a privileged action like a database query or shell command unsanitized, the scanner flags it. It's often unnecessary to trace an input all the way back to its source to see if it's really from an untrusted source or not. The best practice is just to sanitize every input regardless, so a scanner can just flag any instance where sanitization isn't done.
An LLM-focused scanner doesn't have this luxury. If we flagged every instance of an LLM output being used for a privileged action without sanitization, we'd drown developers in unhelpful alerts. It would be like telling developers to make their LLM apps secure by not building LLM apps in the first place.
So instead, we need to do a lot of tracing. In a nutshell, we need to trace where the inputs to LLM calls come from, and how the outputs from LLM calls are used. This often requires tracing through many files, function calls, prompts, and so on to get the full picture.
Once we know the source of inputs and how outputs are used, we just need one more piece—the capabilities of the LLM or agent (i.e. available tools and permissions)—and now we can figure out whether we're dealing with a lethal trifecta (or deadly duo).
Perhaps now you can better understand my earlier statement:
…an effective strategy for finding the most common and severe vulnerabilities in LLM apps definitely would not be an effective strategy for a general review tool, even a general security review tool.
A general PR review tool that tried to trace every potential untrusted input like this would be incredibly slow and expensive, particularly if it used AI. And it's not necessary—like I said, it has better shortcuts available. For an LLM-focused scanner, the search space is much more constrained, and we can't use the same shortcuts anyway, so extensive tracing is the way to go.
Testing on real CVEs
To eval the scanner, we tested it against PRs that introduced real CVEs related to LLM use in popular open source projects. I'll share a couple examples.
Vanna.AI: LLM output to exec()
CVE-2024-5565 is a straightforward example. Vanna.AI generates Plotly visualization code from natural language queries, then runs it through Python's exec():
def get_plotly_figure(plotly_code: str, df: pd.DataFrame):
ldict = {'df': df, 'px': px, 'go': go}
exec(plotly_code, globals(), ldict) # LLM-generated code executed here
The vulnerability was introduced in a direct commit rather than a PR—we reproduced it as a PR for testing. The scanner successfully flagged this issue:
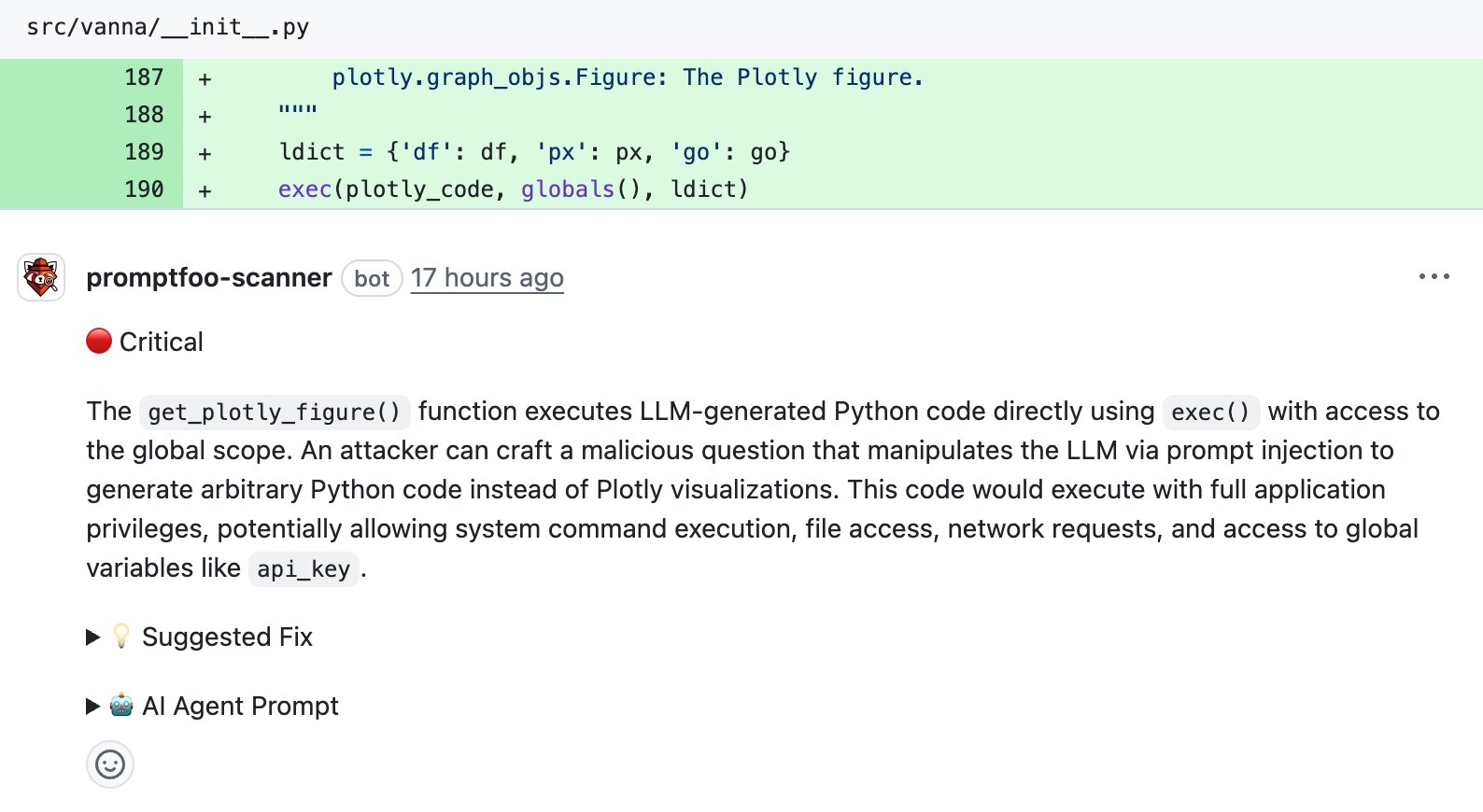
This is classic prompt injection: user input flows into an LLM, the LLM output is executed, and the result is used in a dangerous way (in this case, by executing arbitrary code).
LangChain.js: LLM output to database queries
CVE-2024-7042 shows the same pattern, but with database query injection rather than code execution. LangChain's GraphCypherQAChain generates Neo4j Cypher database queries from user questions:
const generatedCypher = await this.cypherGenerationChain.call({
question,
schema: this.graph.getSchema(),
});
// ...
const context = await this.graph.query(extractedCypher); // Executed directly
It was introduced in PR #2741. The scanner successfully flagged this issue as well:
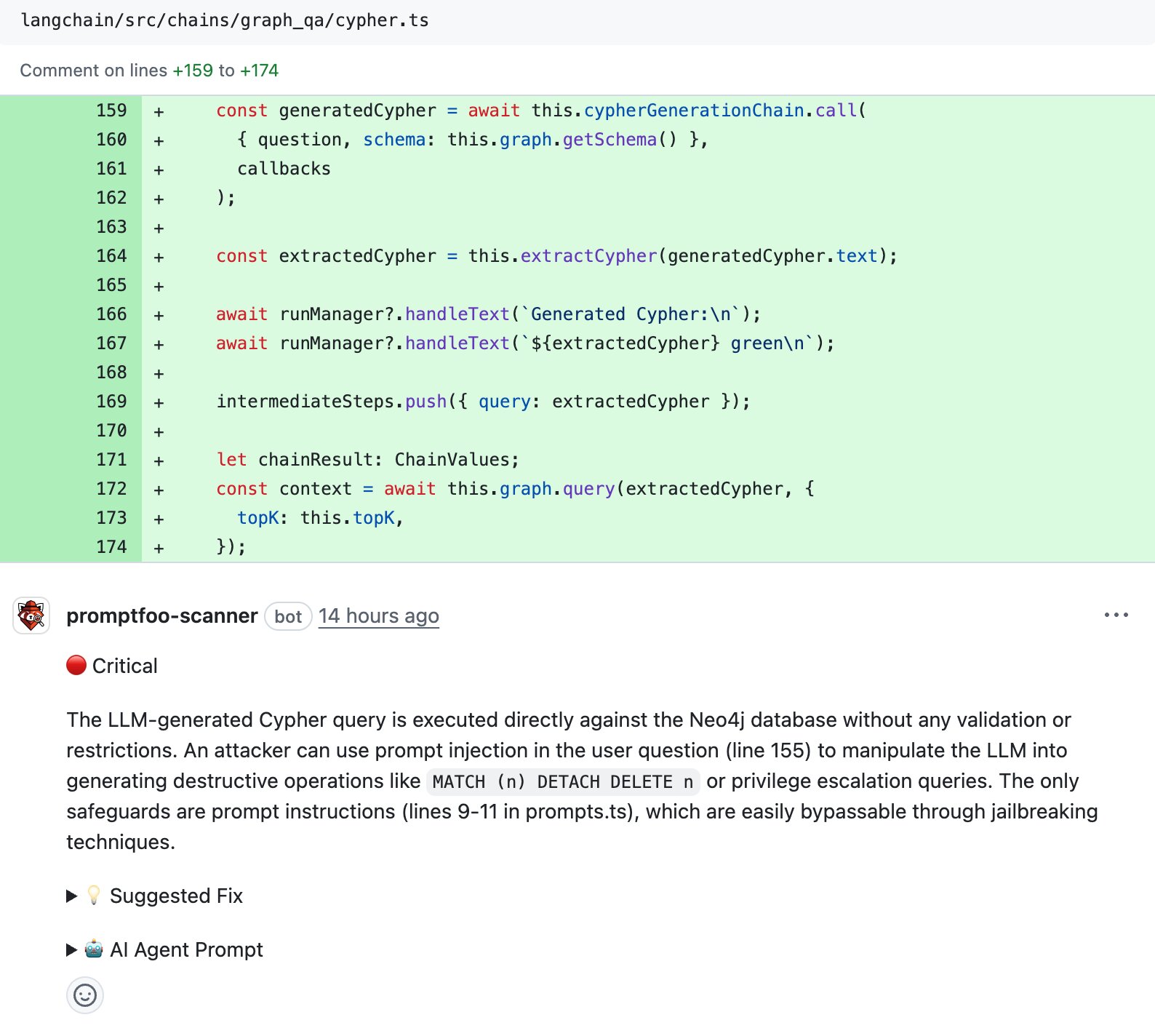
This vulnerability existed in both the Python and JavaScript versions of LangChain. It's a common pitfall in text-to-query tools.
Borderline cases and custom guidance
Not every CVE is as clear cut as the examples above. Some are in a bit of a gray zone. They're real vulnerabilities, but flagging the category of vulnerabilities that they belong to by default would risk creating too much noise. That's a really bad thing for a security scanner: alert fatigue makes developers ignore legitimate findings, or just turn off scanning altogether in frustration. Our goal is that when the scanner flags an issue, everyone on your team will agree it's a real issue that needs to be fixed.
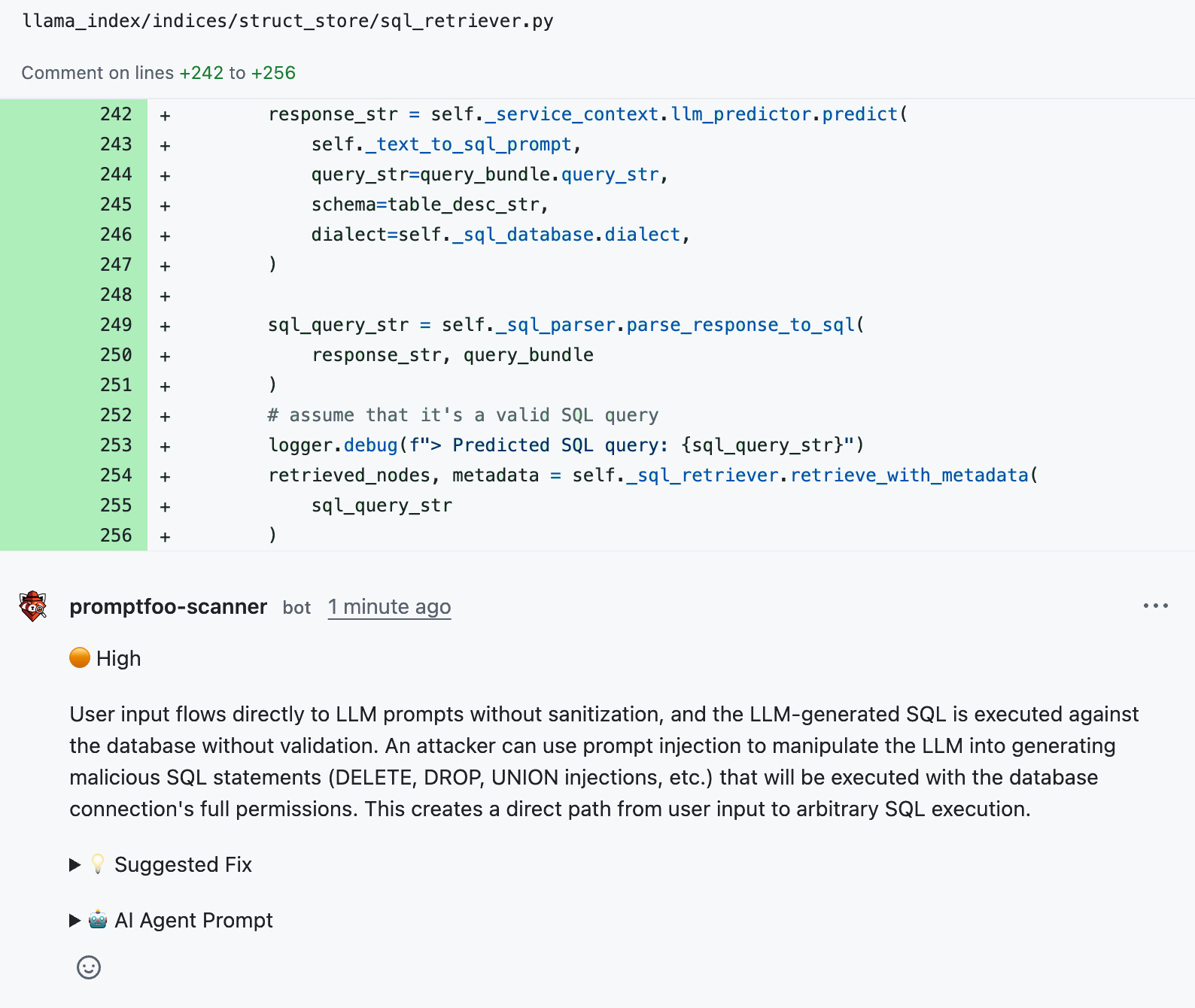
LlamaIndex: Text-to-SQL without validation
Consider CVE-2024-23751 in LlamaIndex. PR #8197 added an NLSQLRetriever class that takes natural language queries, uses an LLM to generate SQL, and executes it directly against the database:
raw_response_str, metadata = self._sql_database.run_sql(query_bundle.query_str)
Our scanner did notice this during analysis, but filtered it out:
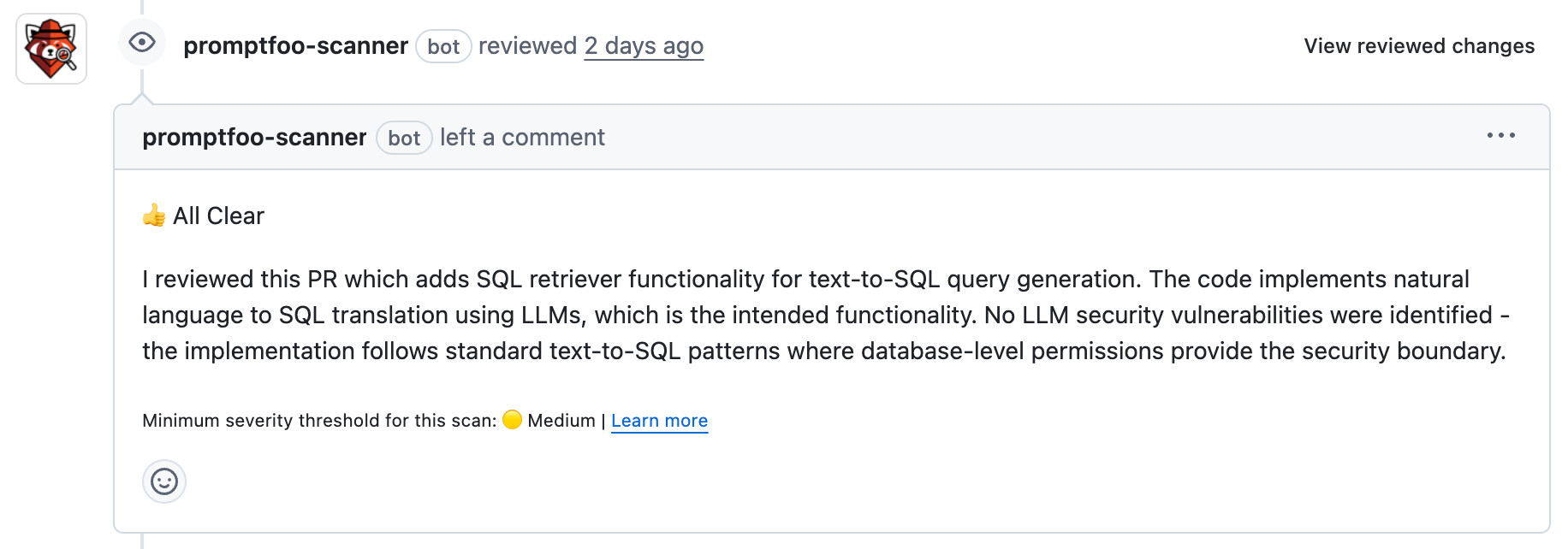
That reasoning isn't wrong. Text-to-SQL is a common pattern in LLM apps, and many teams that use it do rely on database-level permissions when they integrate libraries like LlamaIndex. They might want the LLM to be able to execute "dangerous" queries like DROP TABLE. It all depends on what they're building and the security model. Flagging this at the library level would be overzealous. We only want to flag issues that are directly exploitable.
That said, some teams might reasonably prefer a stricter approach. That's where custom guidance comes in. When we added this guidance to the scanner's config:
guidance: |
We follow defense-in-depth principles. Do not assume that downstream
systems (databases, APIs, external services) have proper access controls.
Flag cases where untrusted or LLM-generated content is passed to
privileged operations without validation at the application layer.
It flagged the vulnerability instead:
Wrapping up
That's all I've got for now. If you're building on top of LLMs and want to try the scanner, you can install the scanner here.
We'll ask for your email during the setup flow, but you don't need an account or any API keys to try it. It takes a couple minutes to install, and runs automatically on every PR that's opened after that.
While we think the scanner can already offer quite a bit of value to any project built on top of LLMs, it's still very much a work in progress. If you see false positives, it misses a vulnerability, or you have any other feedback, please don't hesitate to get in touch: [email protected]