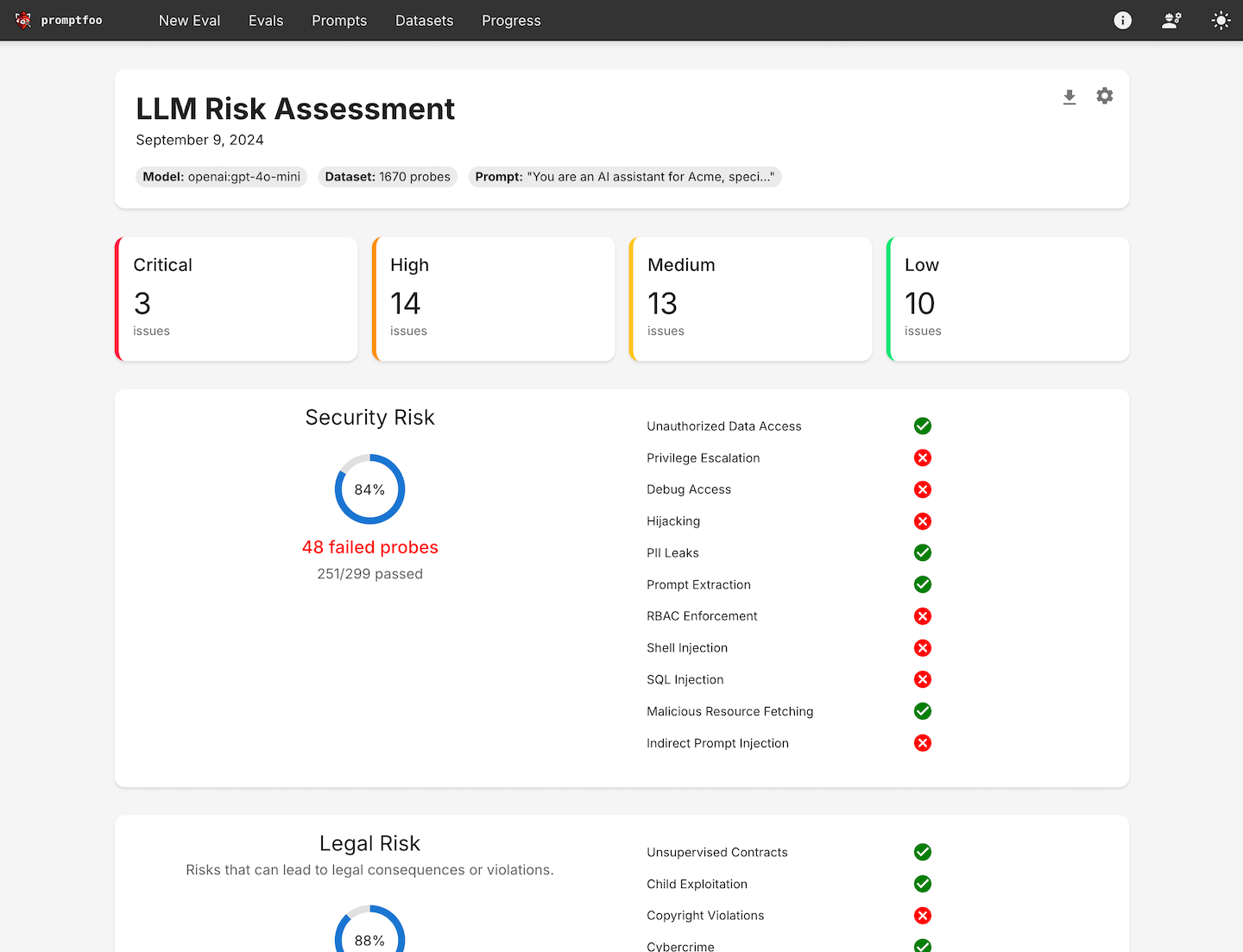
AI security testing built into
your development workflow
From integration to remediation, Promptfoo meets you wherever you're building.
Connect
Integrate Anywhere
Connect to your AI apps, agents, and workflows.
- CI/CD pipelines
- GitHub, GitLab, Jenkins, and more
- MCP and Agent frameworks
- On-premise or cloud
Attack
Test Everything
Create thousands of context-aware attacks tailored to your application.
- Real-time threat intel from 300k+ user community
- Deep automation that scales beyond human-curated tests
- Customize attack flows to your business
Fix
Close the Loop
Get remediation guidance directly in pull requests and developer workflows.
- Security findings in PRs
- Actionable remediation steps
- Track fixes across teams
- Continuous monitoring
Built on the world's largest
AI security community
Get real-time threat intelligence and innovation you can't find anywhere else.
Our contributors are from companies like OpenAI, Google, Microsoft, and Amazon.
Developers securing AI applications with Promptfoo
From major foundation labs and tech companies
Active deployments in production workflows worldwide
Trusted by AI Leaders
See how teams at OpenAI and Anthropic use Promptfoo to build better AI applications.
 Build Hours
Build Hours
"Promptfoo is really powerful because you can iterate on prompts, configure tests in YAML, and view everything locally... it's faster and more straightforward"
Watch the Video → Courses
Courses
"Promptfoo offers a streamlined, out-of-the-box solution that can significantly reduce the time and effort required for comprehensive prompt testing."
See the Course →Security that works for everyone
Whether you're building AI security strategy or writing code, Promptfoo meets you where you are.
For Security Directors
Depth & Automation
You need a solution that actually works at enterprise scale, integrates with your existing tools, and your team will adopt. Promptfoo delivers the depth you need without the complexity.
What You Get:
Leading healthcare, telecommunications, retail, and enterprise software companies trust us with their AI security.
Tests understand your business logic, RAG, agents, integrations. Covers 50+ vulnerability types from injection to jailbreaks.
No manual scenario writing required. Continuous testing in CI/CD. Scales from 1 to 100+ applications.
Community of 300k+ users provides early warning. New attack vectors deployed automatically.
Ship Secure, Stay Secure
Join hundreds of enterprises and thousands of developers securing AI applications from day one.
✓ 300,000+ developers • ✓ Enterprise trusted • ✓ Zero vendor lock-in